各位朋友大家好,今天主要是来分享关于实时音视频与教育的结合。本来最开始的标题是“TRTC与在线教育的那些事儿”,但考虑大家都是做技术的,所以改为“实时视频助力在线教育的新风口”,能力有限,如果有错误与问题,还请多多指教,欢迎一起交流学习。
首先做下自我介绍,我叫蒋磊,现在是腾讯云TRTC客户端的产品架构师。加入腾讯云之前在网易和阿里云,主要从事直播、点播、CDN的技术。加入腾讯云之后主要做的是关于音视频处理这一块的客户端SDK。

今天分享内容主要包括三点。第一个点是关于疫情影响下在线教育市场的变化情况,我们称做井喷,第二点是我们这个项目在此过程中踩坑、填坑的几个案例,以及实践经验分享,最后是我们在在线教育新模式上面的一些尝试与探索。
首先,简单介绍一下我们TRTC这个项目。
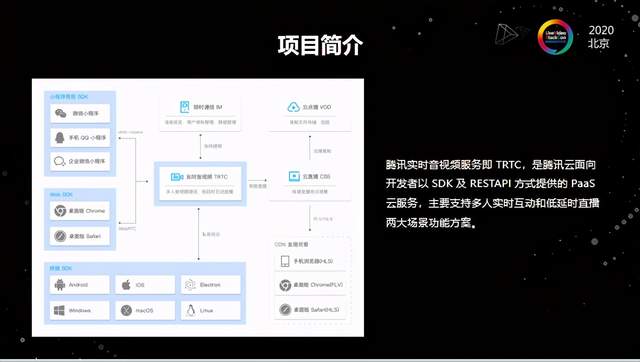
TRTC(Tencent Realtime Communication)全称是腾讯实时音视频,是在腾讯云上以SDK和REST API的方式提供售卖的云服务。我们主打两个场景,一个是多人实时互动,像视频会议、小班课、大班课等,另一种是低延时的直播,像娱乐场景中的语聊房、秀场直播等。这两类场景对延时的要求都比较低。
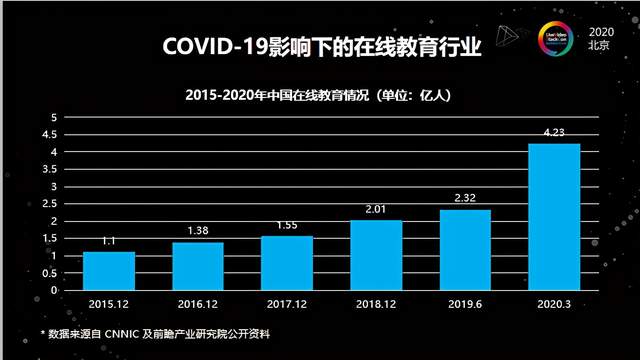
对于在线教育场景,大家今年的感受都比较明显。上图数据来自CNNIC和前瞻研究院的公开数据。原本按照预期,在去年的基础上,普遍认为今年在线教育行业的用户量应该在接近3个亿左右的规模。今年因为疫情的影响,大量的线下场景搬到了线上,疫情期间中国在线网民参与到在线教育的用户数量已经接近于4.3亿。这个数据还仅是截至3月份,应该在4、5月时才算到一个最高峰。早在16、17年就已经出现过一次在线教育的融资热潮,之后平静了一两年,再到今年又一次掀起新的热潮,这一次主要原因在于用户包括学生、家长、各个教育者以及管局都意识到了在线教育的必要性,尤其对线下学校而言,所以说我们将此定义为在线教育的新风口。
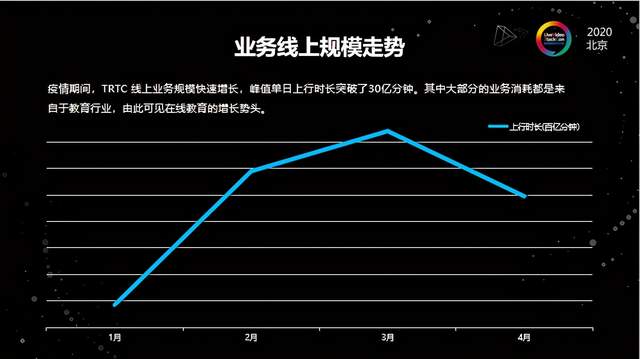
另外一个反映在线教育新风口的点是来自于我们实际的线上数据。大家可以从上图看出TRTC线上规模的增长,我们统计规模的方式是按照上行分钟数。因为TRTC在腾讯内部支持了非常多的业务,包括腾讯会议,腾讯课堂、企业微信、微信都是TRTC在支撑。我们抛开内部用量,单看外部的因素,在峰值的时候,当天的上行超过了30亿分钟,相比之前正常情况下的规模翻了好几倍,而且这中间大部分的增量是来自于在线教育。所以从业务规模走势上我们也能感受到,今年在线教育这个风口来得非常猛烈。

从技术的角度来看,当你的线上规模猛增的时候,很多以前可能没有意识到的小的细节点就会在过程中间不断的暴露出来。第二部分我将重点介绍在这过程中我们遇到的一些实际问题以及解决办法。
2.1 基础能力优化

首先是关于基础能力的优化。在疫情期间,我们遇到有些客户反馈,他们的一些用户用的是iPad mini,性能不是很够,提出是否可以支持320x240分辨率的编解码,而且是要12个人同时在iPad mini上面去做编解码的工作。这就比较麻烦,由于iPad mini是2013年发布的,距今已经7年,它的性能不是那么强,同时做12路编解码的时候,性能上只能说是勉强能用。事实上这个问题在教育环境中是非常普遍的,因为在接触过很多客户之后,我们发现孩子在线课堂上课的设备大多是家长以前用过、闲置下来的设备,这些设备一般都是好几年前的,所以对于应用程序的性能的要求会更高。按照常理来说,这个问题也是比较好解决的,我们可以用硬编硬解来处理。但实际上并不是这么简单,这里面有一点历史给大家介绍一下。
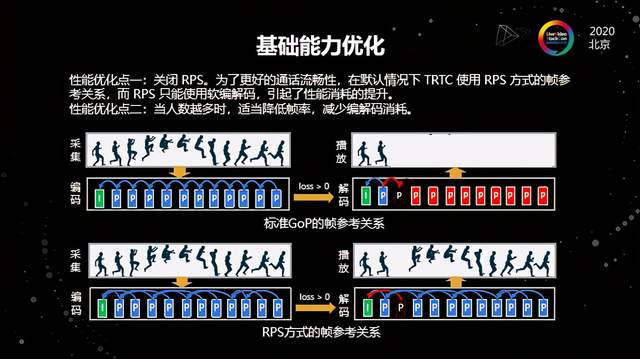
在H.264的标准编解码的参考序列里用的是被我们叫GoP的标准参考关系。在标准的GoP的帧参考关系下,其每一个序列的后一帧是严格地依赖于前一帧的。就比如说网络抖动了一下,可能不是所有的数据全丢了,只是丢了中间某一帧数据,但是丢了这一帧之后,参考关系也会马上丢失,所以哪怕后面的数据全部都过来了,播放端也解码不出来,这就导致用户看到的画面卡了一下。所以之前为了解决这类问题,我们将编解码器的参考方式改为RPS的方式。RPS方式相比于标准GoP的不同之处就在于不要求每一帧严格地依赖于前一帧,它是可以挑选前面的某帧作为依赖。这样当遇到同样的丢包的情况,比如说图中丢了第三帧,只要能够控制好参考关系,不会影响后面的帧继续解码,也就是说从用户的感官上是感觉不到这个视频卡顿的。
但是因为这种方式并不是标准的,所以我们只能用软编软解的方式来做,一般情况在普通的手机和平板上都还好,而且带来更好的弱网抗性,但一旦遇到了像iPad mini同时支持12个人的这种情况,软编软解叠加起来的性能消耗就非常明显,所以我们要做的就是要尝试优化这种通话场景的效果。RPS的引入帮助降低了用户的卡顿率,是具有实际使用效益的,不过为了保证更好的流畅性、控制好低性能设备的消耗,我们就必须要把RPS关掉,切换回原本的GoP的方式,这样才能调用硬编硬解,同时我们还要同步做好参数控制以及网络的调优。这里也给我们自己上了一课,我们之前认为大部分的用户会追求流畅性,所以通过各种技术手段去保障在弱网下尽可能地流畅,但同时也引入了更多的性能消耗,尤其是在低端设备上遇到这种多人的场景,就必须要尝试用更经典的方式换回到以前的硬编硬解的思路,优化更合适的编解码参数控制、更合适的网络参数上面,让我们意识到经典的东西还是很重要的,要把基础打牢。

第二个是另一个场景。疫情期间,一些教辅机构、教育机构希望把线下的场景能够在线上还原,比如1个老师跟30个学生这样非常典型的线下课堂。这里会碰到一个问题就是当所有人的麦都会打开,非常典型的场景是上课的时候同学们齐声喊老师好,这在线下课堂是很常见的,但搬到线上的时候就非常麻烦。因为在客户端去拉取上行数据进行本地播放的时候,如果只是几路音频做混音还好,但如果是三十路很有可能混音出来的声音大家都听不清了,无法分辨老师和同学说的话。尤其这种课堂一般是针对中小学,小学生在上课的时候其实不太能够安静得下来,针对这种场景我们之前没有重点关注到。这样的场景主要有两个点。
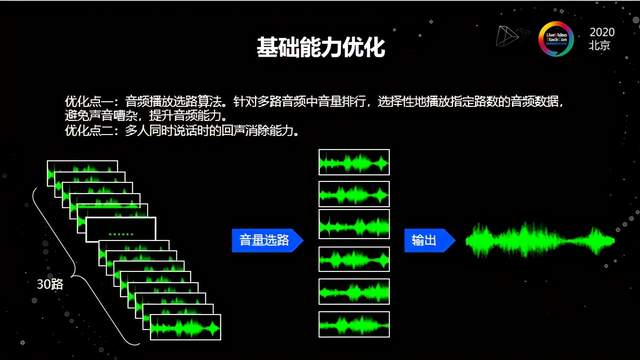
第一个点是做音频播放选路。因为音频最终播放的时候只有一路声音,是经过混音的。在播放前我们必须要对这么多路的音频去做选路,选择中间权重最高的几路进行混音,最终播放出来,这样就能从技术、听感以及用户体验上尽可能保证音视频体验,比如上课时老师权重是最高的。这种方式的技术实现其实是比较复杂的,我们设计了一套音频选路的加权选路算法——选择性去从几十路音频中间抽几路播放出来。

除了做选路以外,另一点是回声消除。因为同时说话是一个非常典型的场景,我们叫做双讲场景——我在说话的时候,远端也在说话,远端的声音就会从我的本地播出来,本地我自己的声音也要采集,这样两边同时说话的时候就会导致对方的声音里面可能会带上自己的声音,对方会听到自己的声音,产生回声。这种情况是音频处理中一个典型的”红蓝墨水分离”问题,我们要做的是从红墨水跟蓝墨水的混合中把各自抽离出来,这在业界是比较典型的难题。腾讯其实在10多年前就开始做音视频技术相关的研究,并在16年组建了音视频实验室,后来改名叫多媒体实验室,它打造了一个TRAE引擎(Tencent of the Realtime Audio Engine)——腾讯实时音频引擎,这个音频引擎主要做3A处理和音效,在行业内都处理于领先水平,对于双讲的处理表现不俗。
2.2 效果与质量检测

除了基础能力以外,大家平时做业务的时候经常会遇到客服接到一些反馈,总结起来有两大部分是要特别关注的。第一个是属于不可用类的问题,比如无声、黑屏等完全不可用的情况,这种我们叫客损。第二种是体验比较差的情况,比如模糊、卡顿,以及包括杂音、回声等在平时上课过程中经常可能接到的反馈。因为客户端的设备非常多,我们无法预测到用户在当下堂课使用什么设备,所以归根起来就是是否能够更好地把控音视频质量以及效果。

针对这个问题,我们在产品的全链路中埋点,引入了一套大数据的分析系统,尽可能早的掌握音视频质量和效果的潜在问题。举个例子,无声现象的典型来源有几个:首先是设备问题,比如麦克风采集不到声音或者扬声器坏了,这是都属于设备故障类;第二是比较常见的网络问题,比如家庭的WiFi可能接入太多设备后,由于路由器本身性能不好,负载过高,从而出现了随机性的丢包或者随机性的高抖动;第三个是打断,比如临时的电话接入、误开第三方App或者进程抢占,都可能会导致课程中断;最后一点是数据处理,比如双讲的剪切、采集播放的音量太小、没有做增益调节等等。
我们针对每一个环节都加了相应的埋点上报,并且在这个环节也提前预置一套解决流程。比如当检测到设备故障,就直接抛出一个回调,告诉用户设备故障;再比如当检测到音频持续为0超过几秒,就会直接警告设备持续无采集、持续音量为0。
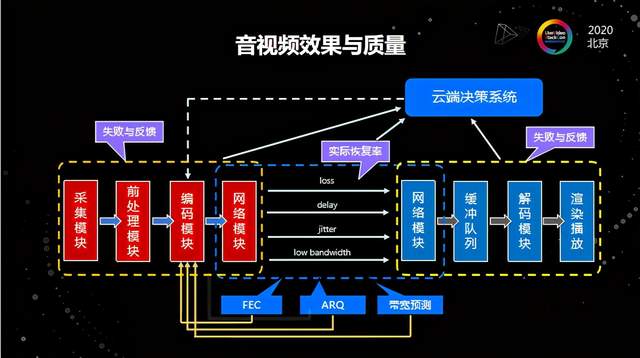
我们根据全链路埋点监控,把所有数据上报,搭建了一套AI模型,也就是云端决策系统,这个系统使用了腾讯自研的质量评估算法,既包括有参考的、也包括无参考的,同时在云端做持续的优化迭代。我们把整个链路中间包括模块处理失败的反馈上报、网络状态、QoE的算法策略等全链路的追踪都做了埋点,这样我们就可以通过这一套系统精确的找出哪一个模块出了问题,以及下一步应该如何改进。
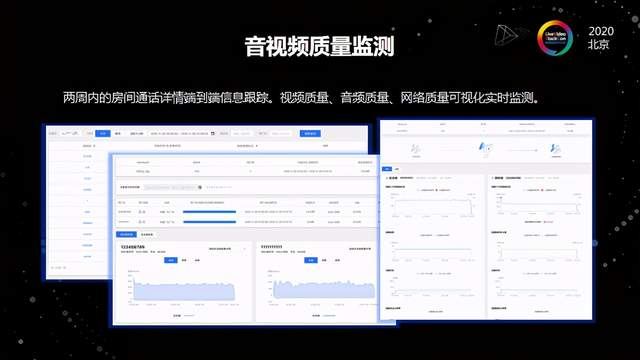
除了全链路埋点监控和云端决策系统,我们针对客户面在TRTC控制台上开放一个Dashboard(监控仪表盘),这个监控仪表盘我们尽可能提供精准简要的数据,并且向用户可视化地开放出来。目前第一期主要做的是通话详情,提供两周之内端到端全链路的通话详情,通过这个仪表盘就能有效获知课堂的整体情况,后续我们还将继续推出更多的能力。
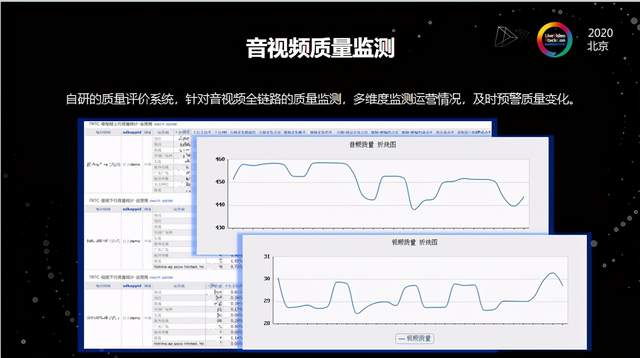
此外我们还做了一套自研评估体系,以此作为内部的预警监控。以Demo为例,我们会从几十个维度做了一整套数据的分析,其中包括音视频卡顿率、缓冲时长、连接成功率等,通过自研的质量评估算法评估音频以及视频的质量,帮助我们更好地知道某一个客户线上的情况到底是怎么样?相比昨天质量是否有下降?下降的原因在哪里?结合前面提到的全链路跟踪,我们就可以在很大程度上分析出来导致质量下降的原因所在。
2.3 组合类场景下的音频优化

第三块是关于组合场景,典型的就是精读课——在老师授课过程中会分享一些课件或者视频,比如在语文学科中就有古诗词诵读的部分,老师会先播放一个视频,然后再对古诗词做讲解,类似的场景还有很多。这其中就会出现一些问题,比如音量大小不一致,老师说话的同时视频也在播放,但视频的声音可能就听不清楚了;还有视频跳音,视频播放过程中突然发现视频的声音卡了一下又跳了;此外还有本地出现回声、音频被打断等等。
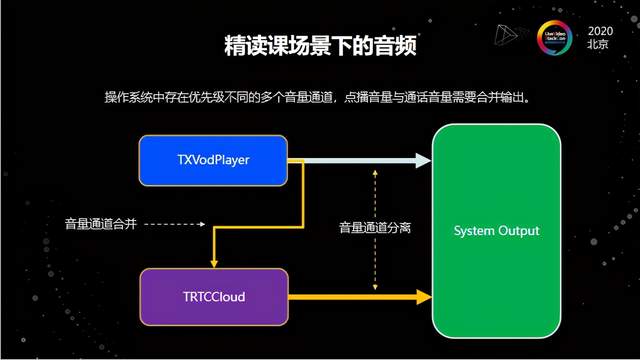
在这种场景下,它主要的问题在于音频。操作系统中间对于音量通道分级的处理不同,以iOS为例,它的音频管理做得非常复杂,会针对不同的音频通道做不同的优先级管理,而且每个音频通道相互之间处于分离的状态,举例来说就是电话和平时播放腾讯视频走的音量通道是不一样的,操作系统会认为这是两个不同的音量,就单独的去处理,然后最终把它从系统的输出送出来,但就是因为音量通道不同,所以在操作系统层面就会做优先级,比如电话的优先级肯定是最高的,其次是闹钟,然后是媒体音量。
媒体音量就是我们平时观看视频或直播的,所以在这种场景下你的播放器一般走的就是媒体音量。但是做RTC的话,我们默认会选择用通话音量来做。但是这两者用了不同的音量通道之后,因为通话音量的优先级更高,就会压制媒体音量通道。而且在做3A处理的时候,比如用硬3A的话,系统会在在输出之前去做3A的对比,然后可以处理好回声;但是用软3A的话,一个APP中RTC进程没有办法拿到另一个进程的音频数据,这样就没有办法把它的回声消掉,从而导致了前面提到的音量不一致以及音量回声没有消除干净等现象。
那最好的解决办法是什么呢?我们把这两个音量通道做了合并,虽然原理很简单,但实际执行起来是非常复杂的,原因首先来自编解码,第二是源于播放器。播放器有非常复杂的业务逻辑,大部分RTC厂商都是先做RTC,然后在它的上面做一个非常简单的播放器,只能用来播放基本的视频、音频内容。但是我们已经有一套非常完整的播放器,跟RTC要完全融合的话,中间会有比较大的改造量,两者的融合需要把整个播放器底层的音频完整替换掉,并且保证它能够跟RTC用起来。

解决这个场景要做到两点,一款高效好用的播放器以及一套十分稳定的RTC客户端。我们在17年的时候就已经做了一套非常完整、高效好用的TXVodPlayer,这个播放器现在非常多的用户都在用,而另一方面TRTC今年支撑了非常多的内部业务以及外部业务。那么当这两者很好地结合起来,我们才认为真正的解决了精读课这一场景。

以上是我们疫情期间在教育行业实践中踩过的坑以及优化方案。除了底层技术的优化,我们也和客户一起探索了新的场景,今天主要介绍两个方向,一个是AI老师课堂,另一个是超级小班课。
3.1 AI老师课堂
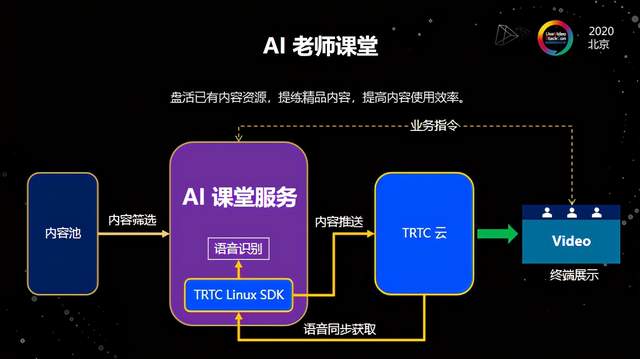
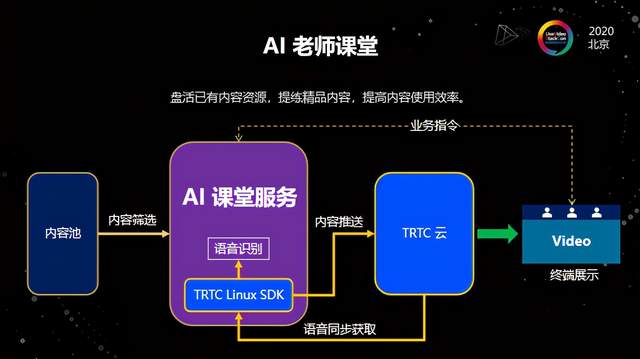
我们第一次接到这个需求的时候,和客户讨论了很长时间,从技术产品的角度出发其实并不困难,重点在于它是不是一个伪需求。经过和多家客户讨论,我们都认为它是真正存在痛点的需求。比如一些教辅机构多年运营积累了非常多精华的课程内容,他们希望能够把这些内容合理地利用起来,提高使用效率;同时对学生而言,一些新老师讲授的内容并不一定有以前经典的讲得那么好,学生也希望能够接受更好的教学资源,所以在这一点上AI课堂能够发挥很好的作用。
AI课堂技术实现最主要的就是两个方面。首先是AI算法识别,我们给视频打标签,识别学生的语音反馈,然后推送相应的内容;另一方面是要有稳定的RTC,这种情况下肯定无法在客户端去做推送,而是要在服务端把推送服务集成进去,然后通过AI识别之后,要有交互的过程,所以我们做了一套Linux SDK。这一套Linux SDK的主要作用是输入输出。通过Linux SDK这种方式来解决推送以及拉取视频、音频的问题。这样就实现了用户在上课的时候能够把语音反馈实时识别,然后到AI课堂服务识别后挑选对应标签的视频推送给用户。从用户体验角度,只要视频剪辑比较好的话,用户是感受不到中间跳转的问题。而且因为是通过RTC的方式来做的,所以在平滑度、自然度上做得是非常好的。
3.2 超级小班课
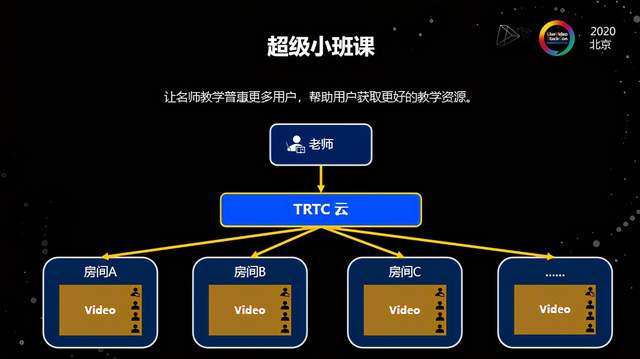
第二个场景创新是关于超级小班课。在教育行业一方面是内容特别重要,另一方面是老师特别重要。培养一个好的老师需要花费大量的人力物力财力,因此就出现了一个好老师同时给多个学生上课的需求,由此提出了超级小班课的概念——一个老师会同步给很多组学生上课,每个组有3-4名学生,在这过程中每一个学生都能到得答疑的机会,还能够自由地跟老师互动。
这个场景的主要问题在于传统RTC是基于房间的,所以一个老师往往只能在一个房间,这种情况下需要将老师的流扩散出去,房间只是作为一个标记。那么通过对房间逻辑的优化,我们可以让一个用户同时存在于多个逻辑房间,从而解决这个问题。

最后感谢信任我们的客户,虽然TRTC已经在腾讯内部服务了很多年,但正式对外是在2019年,企业服务相比内部服务有很多的东西是之前没有预想到的,所以非常感谢客户能够在这个过程中间与我们一起把技术产品踏实落地,也欢迎大家给我们多提出一些宝贵的意见,让我们可以更好地去改进,谢谢大家。

@2017-2024 LiveVideoStack版权所有. 京ICP备20010033号-1  京公网安备 11010502042092号
京公网安备 11010502042092号








