//
编者按: 实况直播业务随着流媒体市场的发展增长迅速。与传统流媒体“一对多”的模式不同,直播流媒体高交互的特性和 “多对多”的架构对时延的要求越来越高,传统基础设施部署和硬件已经不能高效处理这类需求。在此背景下,AMD专为直播互动流媒体处理打造的新一代Alveo™ MA35D加速卡应运而生。LiveVideoStackCon 2023 上海站邀请了来自AMD AECG的谢旻,为大家分享关于MA35D的基本架构和功能,以及该卡在各个领域视频解决方案中的应用。
文/谢旻
整理/LiveVideoStack
大家好,我是来自AMD AECG数据中心的系统架构师谢旻,AECG的前身即FPGA厂商赛灵思,我所在的小组主要负责数据中心计算、网络和存储方向的研发工作。本次要和大家分享的是AMD近期推出的新一代多媒体视频加速卡,它主要应用于视频处理场景,我们内部将它称为异构加速卡,行业同仁更认可将其称作视频处理单元(VPU)。AMD或赛灵思此前的主要业务方向是研发数据中心级加速器卡,因而大家可能对此次媒体加速卡的发布感到惊讶,实际上这背后伴随着深厚的研发背景。
赛灵思时期,我们的目标是实现FPGA在数据中心的算力落地,通过将FPGA包装为PCIE扩展卡并部署在服务器上,使客户可以按照自身需求调用加速卡的算力,最终推出了Alveo系列加速卡U200、U250和U280。
随着FaaS(FPGA as a service)的落地,我们的工作进一步转向应用化并发现了媒体加速方面的前景,因而开始进行编解码器和IP核的自研设计。赛灵思还专门收购了编解码器公司以推动VPU的开发,从而促成了上一代视频流加速器卡U30和U50的诞生。
我们认为,虽然传统的流媒体服务以及相关的视频处理、压缩是在服务器级CPU上的软件中完成的。但随着分辨率的增加,帧数要求提高,流媒体体量的增加,直播和互动流应用对低延迟的要求变得更加严格,传统的CPU不能高效地处理这种场景。因而我们开始寻求异构加速的方法,用专业的芯片/IP来处理视频流。
基于以上背景,我们认为下一代视频加速卡要支持高质量、高密度、低时延的视频处理,并要具备更好的拓展性,才能满足当前低延时、高交互、大流量多媒体应用环境的需要。

我们将此次推出的新一代加速卡命名为Alveo MA35D Media Accelerator,它是业界首款基于ASIC的5nm视频加速卡,在我们内部的芯片代号为supernova。
与我们上一代产品(Alveo U30)和传统Xilinx芯片的联系不同,它完全脱离了 FPGA,是一个专门应用于交互式流媒体大规模应用场景的针对性解决方案。它内部包含很多专用视频单元和最先进的IP核,通过PCIE Gen 5.0和LPDDR5保证带宽,充分助力视频加速服务。
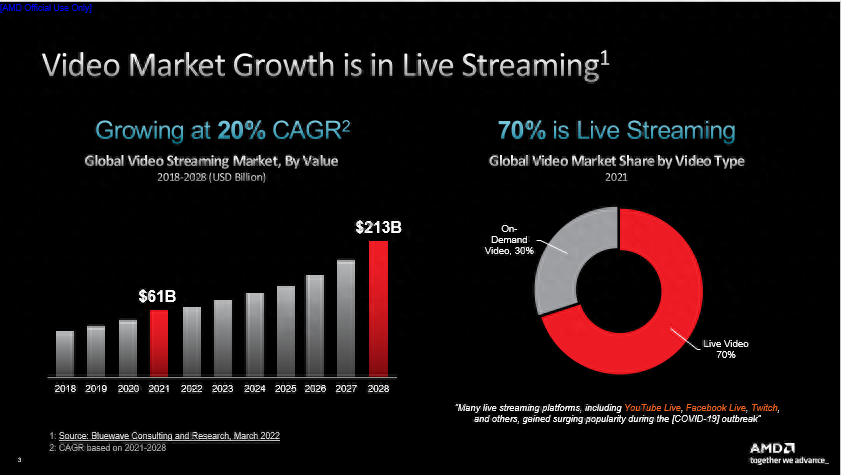
Bluewave Consulting发布的调研成果促使我们下定决心推出新一代流媒体加速卡,该项研究指出了两点,一是全球视频流媒体市场正在快速增长。据预测,流媒体的市场价值将从 2022 年的略高于 600 亿美元增至 2028 年的超过 2130 亿美元,复合年增长率约为 20%。在美国这很大程度上要归功于 Netflix、Amazon Prime、Hulu、Disney+、HBO 等服务商,国内现阶段也存在诸如优酷、腾讯、爱奇艺、抖音、快手、Bilibili等大量视频平台,甚至微博、微信和知乎等应用也在逐步推出流媒体服务,几乎所有公司都在进行流媒体方向的尝试。
二是流媒体服务正在迎来转型。随着流媒体市场的增长,直播业务所占份额越来越大(例如国内的抖音等直播平台),至2021年已占到总量的70%。
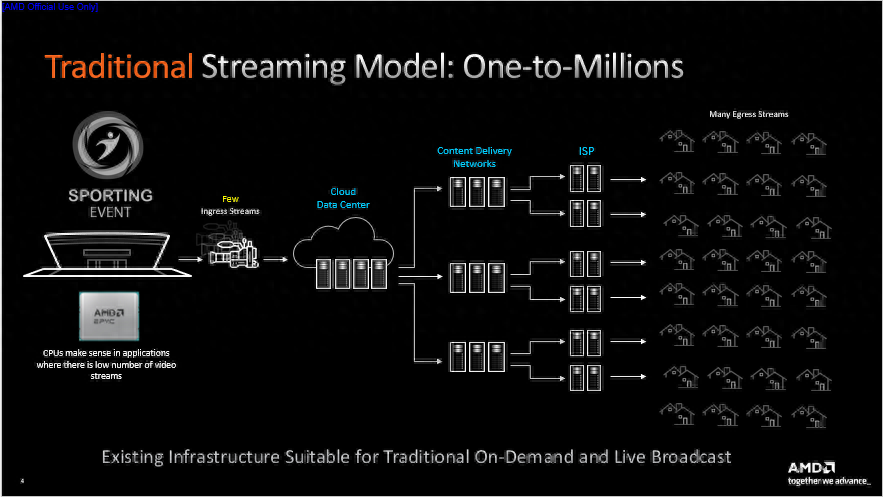
传统流媒体服务架构的形式为广播流媒体,是“一对百万”的模式,该架构下视频的输入源一般较少。以体育赛事的转播场景为例,场外的转播车组织现场的数十台摄像机拍摄赛事画面,经过剪辑上传至云端数据中心/核心网,过程中传输的流相对并不多。随后视频流被分发至CDN,广大用户通过ISP访问CDN获取视频画面。
虽然整个传输路径较长,延迟相对较大,但该场景对实时性的要求不大,并且时延相对可控。同时由于输入流较少,因而对转码的要求也不高。

迅猛增长的直播市场与传统点播场景不同,每个人都能生成自己的流媒体,个人产生的视频流可能与其他流混同,被不同人群在不同地点使用各异的终端设备观看,过程中还伴随着低时延和高交互等等要求。
这种场景的实际应用也越来越多,如online party、远程医疗、云游戏场景和Zoom、Microsoft Teams等在线会议软件。不同用户使用的设备可能不同,导致输入源的格式、清晰度等等属性五花八门。而以上场景都具备高交互性,对时延的要求相当高(如云游戏的时延要在10毫秒内),因而我们希望研发新一代芯片,能够实现低时延、高容量、多路输入(不同格式,不同速率,不同size)、多路输出、多流交互的视频处理。
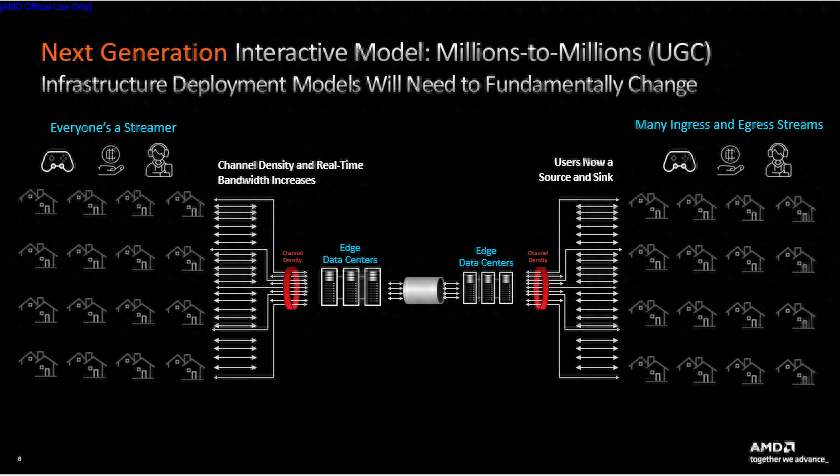
新一代直播场景是“百万对百万”的多对多模式。由于每个人都会产生视频流,流的数量将进一步增加,并且突发式的增长会越来越多。直播的高交互性使视频流传输可能将更多采用边到边传输,避免发送至云端数据中心。用户们使用的终端设备不尽相同,对视频流分辨率和码率的要求也不一样。

为了应对直播场景带来的技术挑战,Alveo MA35D支持32路流的1080P60 ABR转码;每通道功耗仅有1W,峰值功耗约35W;4K编码的最低延时达到8毫秒,1080P可以做到单帧2ms;支持做成单个U.2/M.2 的子卡或是多卡集成部署,支持笔记本、平板、园区、数据中心等多种不同部署环境,适配用户的不同需求。与此同时,它还具备22 TOPS AI算力(INT8),可以通过AI技术来赋能智能视频处理。

上一代U30的“U”代表通用,而MA35D的“MA”代表媒体加速器(Media Accelerator),表示该卡专为媒体加速场景设计。和上一代相比,MA35D实现了全面提升,它的通道密度提高了 4 倍,每通道功耗降低2倍,压缩效率效果提高2倍,时延降低4倍。在实现以上提升的基础上,功耗仅为上一代的一半。
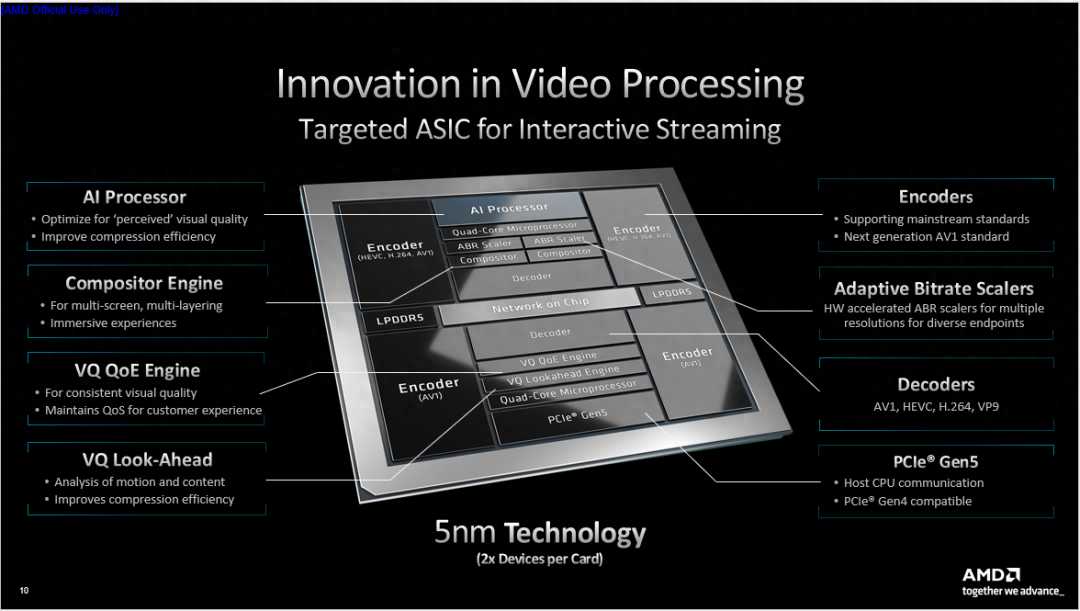
接下来介绍该卡的技术细节。首先四个位于该卡芯片四角的独立编码器和两个解码器支持当前主流编码标准和下一代AV1标准;自适应比特率(ABR)缩放器支持变码率、恒定QP、CBR、VBR等多样化变换;合成器(Compositor)引擎支持多流分块拼接、分层叠加等视频合成处理,它是可编程的,可按照客户自身需求改变输出;VQ 前瞻(Look-Ahead)引擎用于在编码前分析视频流的动态特征,配合编码器实时优化参数;视频质量(VQ)和体验质量(QoE)引擎作为在线质量分析引擎可以将编码后视频的质量分析结果实时反馈至编码器和AI模块,动态调整编码器设置以达到更好的视频输出质量;AI处理器可以对视频进行一些简单的分类和检测处理,依据结果实时调整编码器参数,改善视频质量。
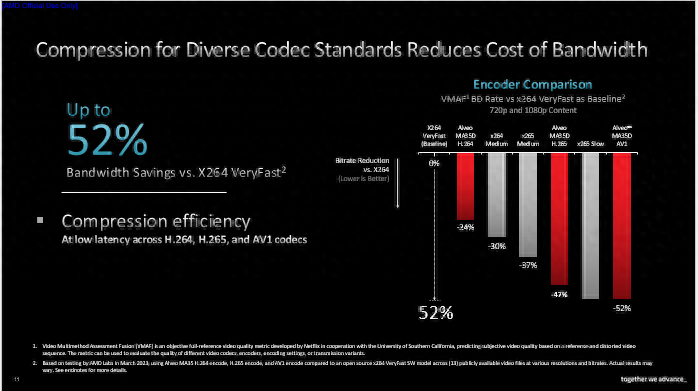
我们也致力于改善编解码器的压缩效率。据AMD内部测试结果显示,在达到同等视觉质量的前提下,以X264 VeryFast为基准对比,AMD H.264编码器可实现24%的码率节省,H.265编码器可节省47%,AV1编码器可节省高达52%。如果加入AI处理环节,压缩效率还将进一步提升。
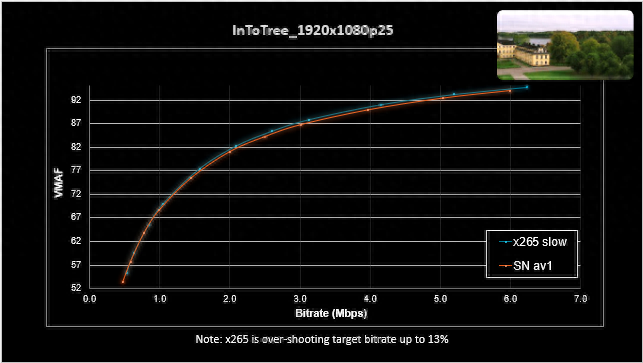
上图展示了X265和AMD AV1编码相同视频的实测VMAF测试结果。可以看到在同等条件下,AMD AV1编码视频的质量接近于X265 Slow,尤其在码率较低时表现相当好。
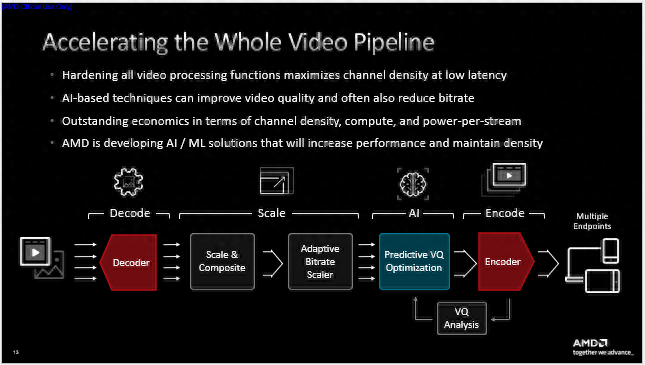
AMD深度耦合前述的各类硬件单元形成了上图所示的视频处理管道,视频解码、缩放与合成、ABR缩放、AI处理、编码、质量分析等步骤全部由硬件单元完成,通过将所有视频处理功能硬化来最大限度减少CPU和加速卡之间的数据迁移。

在云游戏和直播场景,大家可能遇到过画面内字符显示不清晰的问题,运用前述的AI技术则可对字符所在区域进行显示质量的针对性优化。
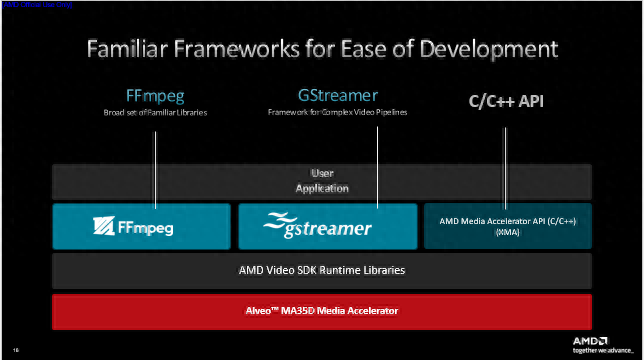
用户可通过我们随卡附带的AMD媒体加速软件开发套件(SDK)访问加速卡,它带有FFmpeg、GStreamer接口,便于快速上手。高阶用户还可以通过AMD 媒体加速器接口客制化调用加速卡的各种视频处理模块。
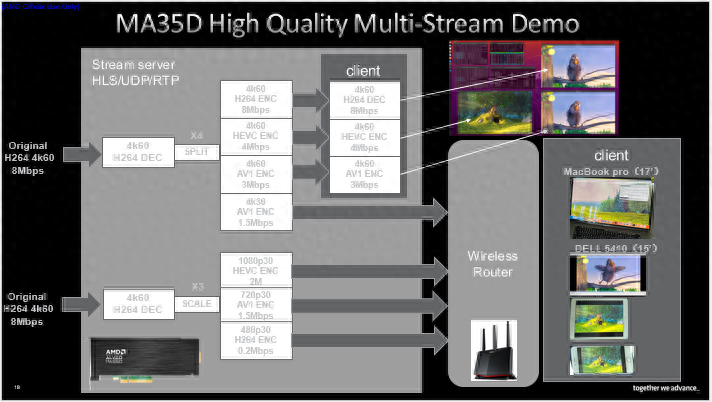
接下来介绍MA35D的一次视频处理性能演示,我们使用单卡双芯片同时处理两个4k60 8Mps H264流。其中一路解码后分为四个流以不同码率和编码标准输出,四个流中的三个在同服务器上使用加速卡自带解码器进行转码、编码,传输至显示器。另一路分为三个流按不同分辨率、码率和编码标准输出,同第一路中的第四个流一并无线传输至不同设备解码显示。

如上所示,演示过程中第一路流在同服务器下的转码和解码都达到了60fps水平,并且转码占用的CPU核1负载不大,核2到核8负责将解码后YUV数据转移至显卡,因而出现了高负载情况。处理过程中的加速卡资源占用情况支持随时调取查看。

上图展示了演示的实时多流多终端传输显示效果。我今天的分享就到这里,谢谢大家。









 京公网安备 11010502042092号
京公网安备 11010502042092号