作者 | Fengjiao Peng
译者 | 姜金元
技术审校 | 曾凯
影音探索#004#——Mimir
据思科公司的一项调查显示:到2022年,视频将占到所有消费者互联网流量的82%以上,比2017年增长了15倍。现在人们随时随地都可以观看视频,比如在家使用Wi-Fi、在手机上、在火车上,在城市里和山间;晚饭后,全家人一起在网上观看视频,或者当孩子们熟睡以后,在凌晨三点观看视频。这些网络条件的多样性给在线视频流带来了前所未有的挑战。
截至2020年12月31日,Vimeo视频播放器每个月要支持高达1000亿次播放,每天有29.7万个新视频上传到我们的平台。高分辨率和无缝播放体验对于创作者的成功来说至关重要。我们付出了很多努力来优化观看体验,从存储层的分配、CDN的选择和交付,到构建超轻量级播放器的算法效率的提高,而设计一个好的视频流算法则是最重要的方面之一。
ABR(自适应码率技术)是现代引领无缝观影的主流技术。在早期的顺序流式传输(progressive streaming)中,CDN是将整个视频封装起来并通过一个转码器将视频交付给用户。在自适应流媒体会话中,视频被分割成了短的切片,对于大多数的商业播放器来说,该切片的长度为3或6秒。每个视频切片都有不同质量的转码版本可供选择,包括360p、720p、1080p等。对于每个切片,ABR算法通过衡量当前的带宽和吞吐量来选择最合适的质量档位(如图1)。
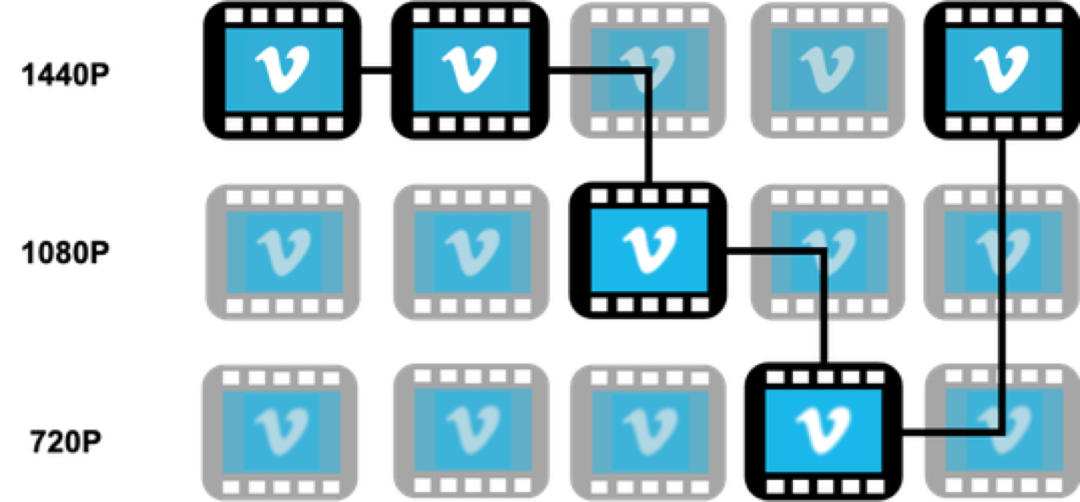
图1: ABR技术。每个电影片段代表一个切片。在播放过程中,ABR算法可以根据网络条件上下切换画质,以确保更好的观看体验。在上图中,视频质量从1440p切换到720p。
为了优化用户QoE(衡量用户观看体验的质量高低的指标),ABR算法的目标其实是相互矛盾的: 我们希望尽可能提供最高质量的视频,但是下载一个尺寸超过吞吐量的视频切片又会导致延迟的发生。当带宽发生变化时,我们希望通过上下切换质量档位来自适应它,但是不必要的档位切换也会影响到QoE。该算法需要注意的是所有通用的QoE标准,而不是过分侧重其中的某一个。
在Vimeo,我们对良好的播放体验作了以下定义:
首屏快速打开:一般的经验法则是,如果一个页面或视频加载时间超过3秒,有超过50%的概率会被用户放弃。
保持首屏高质量:并在整个视频播放过程一直延续高质量播放。
无卡顿:在播放过程中,无卡帧和缓冲情况。
最小档位切换:无缝播放是关键。
为了达到这些目标,我们开发了一个强化学习算法——Mimir。这是一个适用于Vimeo播放器的通用ABR解决方案,该算法能自适应全球不同网络状况和全天的网络波动。
我们使用A3C算法(Asynchronous Actor-Critic Agents)来作为我们的学习框架,其中多个agent在独立、异步的环境中工作,采集数据并更新中央agent。关于A3C的更多具体细节,可以参考Volodymyr Mnih等人提出的“Asynchronous Methods for Deep Reinforcement Learning”[1]。我们从Vimeo数以百万计的真实播放会话中采集数据并使用这些数据在一个离线播放器中模拟真实的播放情况,而播放环境被编程为真实播放器在实际中的播放状态。在训练中,通过环境模拟播放会话并生成当前状态的快照,包括观察到的历史吞吐量、过去的视频切片大小、下载时间、当前缓冲区大小等(如图2)。这些状态会发送到agent,从而形成一个行动者网络(actor network)。然后行动者采取某个行动,例如为当前切片选择某一档位。网络环境执行该动作,并记录奖励r,这是所有QoE指标的总和。当一个会话结束时,该行动会有一个累积的奖励R,以此来衡量这次行动的长期表现。评估网络(critic network)通过对比该状态的平均奖励v和奖励R来进行评估。在每个会话结束时,行动和奖励被发送回中央agent。中央agent执行梯度下降算法(gradient descent)来更新自己的参数,然后将自己复制给行动者,如此循环往复。
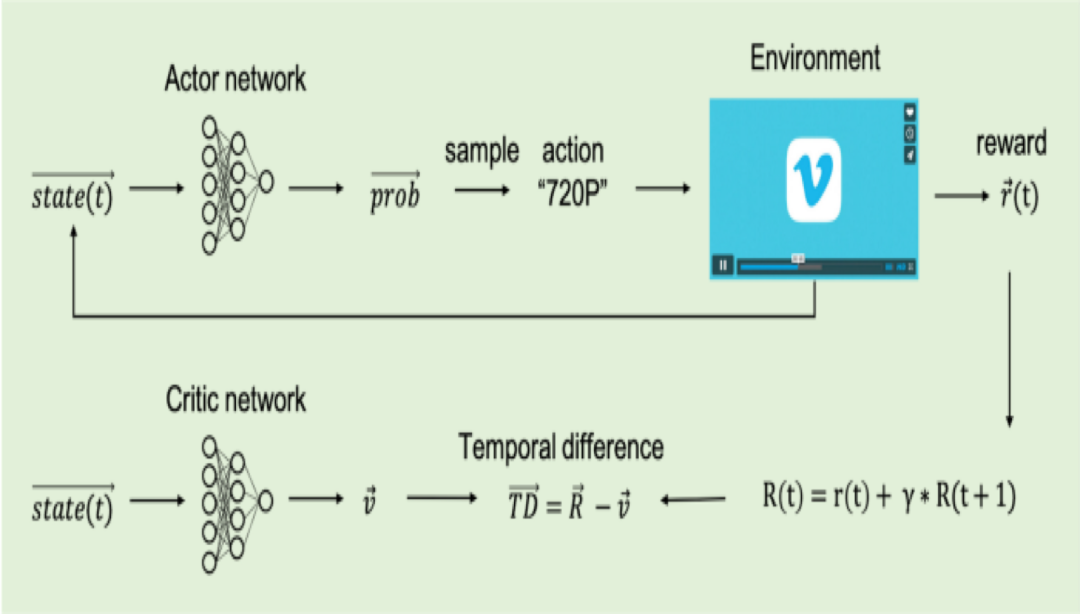
图2:训练循环
Mimir的成功源于四个重要的设计决策:
建立正确的奖励模型
为agent提供大量信息,用以模拟下载时间
编程实现尽可能接近真实播放器环境
均衡训练数据
某个强化学习agent在模拟环境中训练后,再被部署到现实环境中,往往会出现训练偏差。Vimeo播放器包含一组非常明确的规则,用于在小缓冲区的约束下下载和播放视频。例如,当一个视频切片的下载时间超过8秒时,就会发生下载超时错误。遇到这个错误时,播放器会丢弃已经为该切片下载的数据,并以较小的码率重新请求整个切片。在训练中,agent需要通过将错误(当下载时间超过8秒时下载失败的情况)反映在奖励中来学习。
奖励r将用户感知到的QoE告知agent。结合我们在最近工作中看过的结果,我们将其表述为:
r = αQ( ) + βR( ) + γS( ) + (播放器自定义规则)
其中_Q()_是与切片档位(240p、360p、720p 等)线性相关的正奖励;_R()_是重新缓冲的长度,以秒为单位;_S()_是档位切换的步长(例如,如果从 1080p 切换到 720p,则步长为 720 − 1080 = −360)。_R()_和_S()_是惩罚项,因此总是负数,α、_β_和_γ_是加权参数。在实践中,用户感知到的视频质量与视频的分辨率不一定呈线性关系,线性函数_Q()_也只是一个简化的假设。随着转码技术的发展,通过部署将视觉感知和注意力考虑在内的智能算法,一些低质量的转码也可以看起来非常好,这也是Vimeo研究的另一个重要主题!有些用户可能更喜欢带有绝对零缓冲体验的较低质量的视频,其他用户则可能更愿意忍受一些缓冲来观看更高质量的视频。还有一件重要的事,不管你怎么写成本函数,Mimir都表现得很好,这也使得更改这些规则变得非常容易。(有关商业模式和用户画像如何影响QoE定义的更多信息,请查看 Steve Robertson’s Demuxed 2018 talk [2]。)
自定义播放器规则依赖于播放器,包含任意的奖励或惩罚。在Vimeo播放器中,它们是:
视频首屏奖励:如果该切片是视频的前几个片段,奖励更高的质量。
下载超时惩罚:如果存在下载超时错误,那么该视频切片实际上是无法下载的,所以这个惩罚抵消了_Q()_,也是对消耗过多CDN成本的惩罚。
在传统的 ABR 算法中,这些规则很难插入到现有的优化逻辑中。而这些规则正是强化学习算法大放异彩的地方!在模拟测试中,与基于吞吐量算法的baseline相比,Mimir在获得的总奖励方面提升了26 ±3%,重新缓冲的情况减少了69%。
在图3所示的测试播放过程中,吞吐量(紫线)在1~4 Mbps之间快速波动,像这样的快速波动在高峰时段是经常发生的。Mimir始终在传输720p的视频流。当蓝线下降时,它遇到了两个超时事件,分别在67秒和162秒的时候,但它会迅速将一个视频切片的质量调整到240p来恢复缓冲区,因此没有发生重新缓冲的错误。相比之下,baseline是一种基于吞吐量的算法,无法持续传输高质量视频,并且在错误地切换到更高质量后,会发生重新缓冲错误。请注意,baseline算法是如何连续发生两个超时错误的。第一次超时错误之后,如果不经过手动编程,它是无法降低视频质量的。
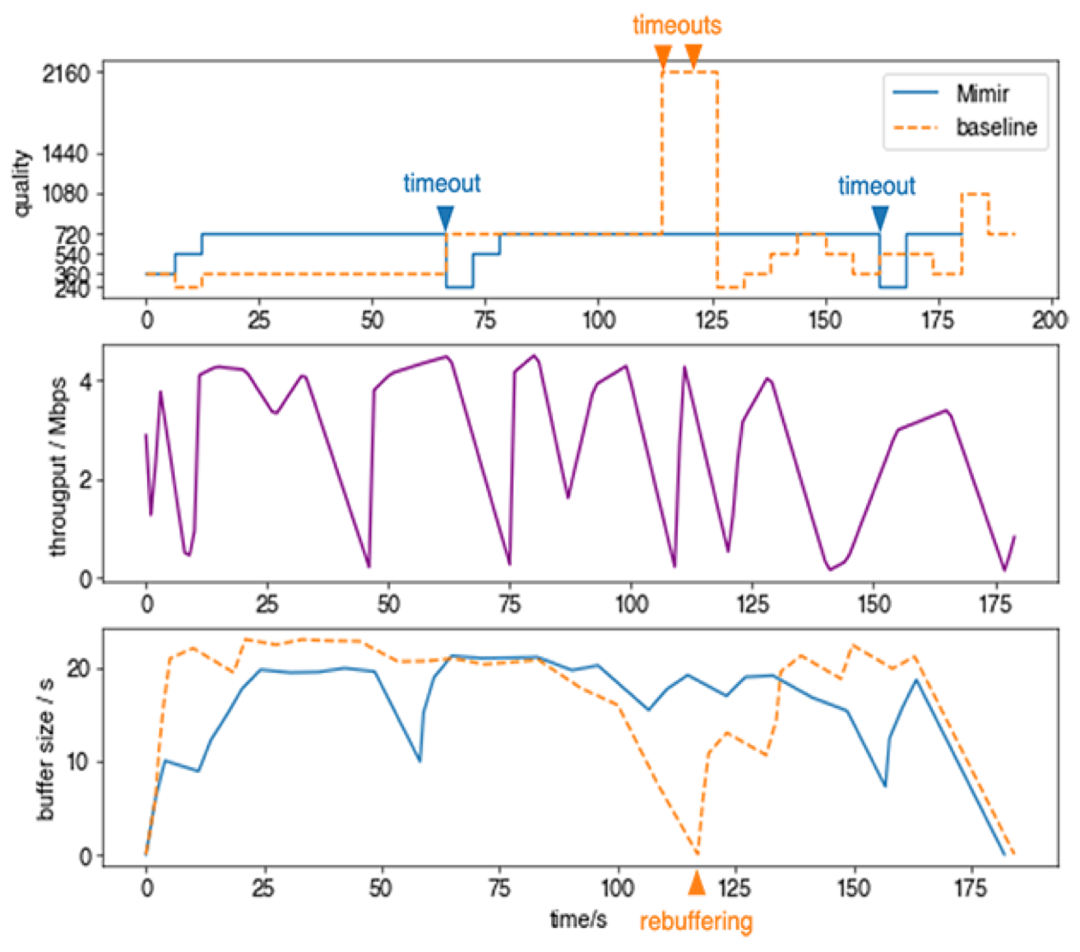
图3: 播放过程测试
在图 4 所示的第二个播放过程中,吞吐量的波动较小,但随后出现了一次大幅下降。Mimir始终保持540p的视频传输,在缓冲区建立之后,开始传输720p的视频。在首屏开启时,它所传输的视频质量比baseline算法更高。在约140秒吞吐量下降时,Mimir会通过降低视频质量以将缓冲区大小保持在零以上。在数学方面,Mimir试图最大限度地延长播放高质量视频 (720p)的时间。对于不喜欢视频质量突然下降和恢复的用户,也可以训练它一直播放540p的视频。
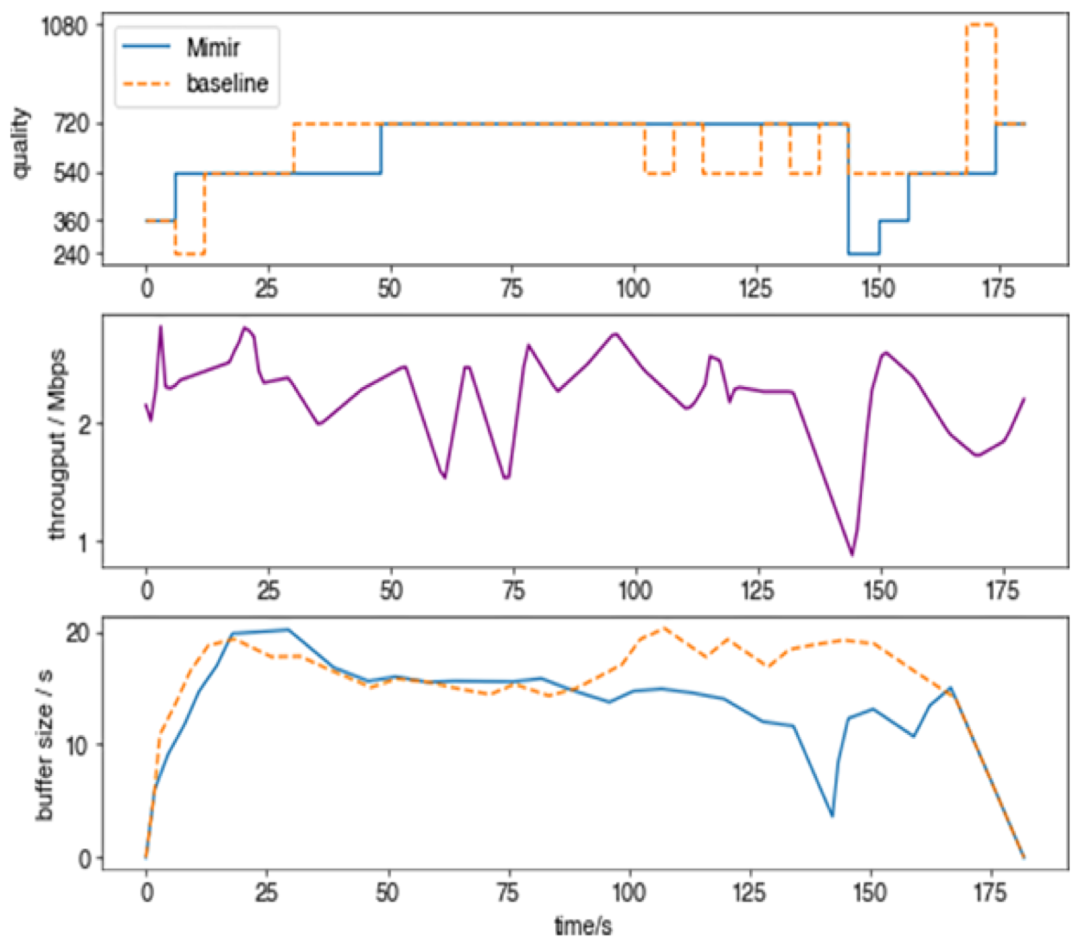
图4: 第二个播放过程测试
图5所示,在会话中下载超时后Mimir的行动分布图,该会话以大约16Mbps的速度稳定地传输1080p的视频。Mimir是不知道当前确切吞吐量的,因此根据剩余缓冲区大小(以秒为单位)来决定下一个质量是多少。如果缓冲区中还剩15秒(带有15s标签的蓝线),Mimir大约有45%的概率会继续选择1080p。如果缓冲区中还剩 6或7秒,Mimir会将码率降低到720p。如果缓冲区只剩下几秒钟,Mimir会将码率降低到240p。
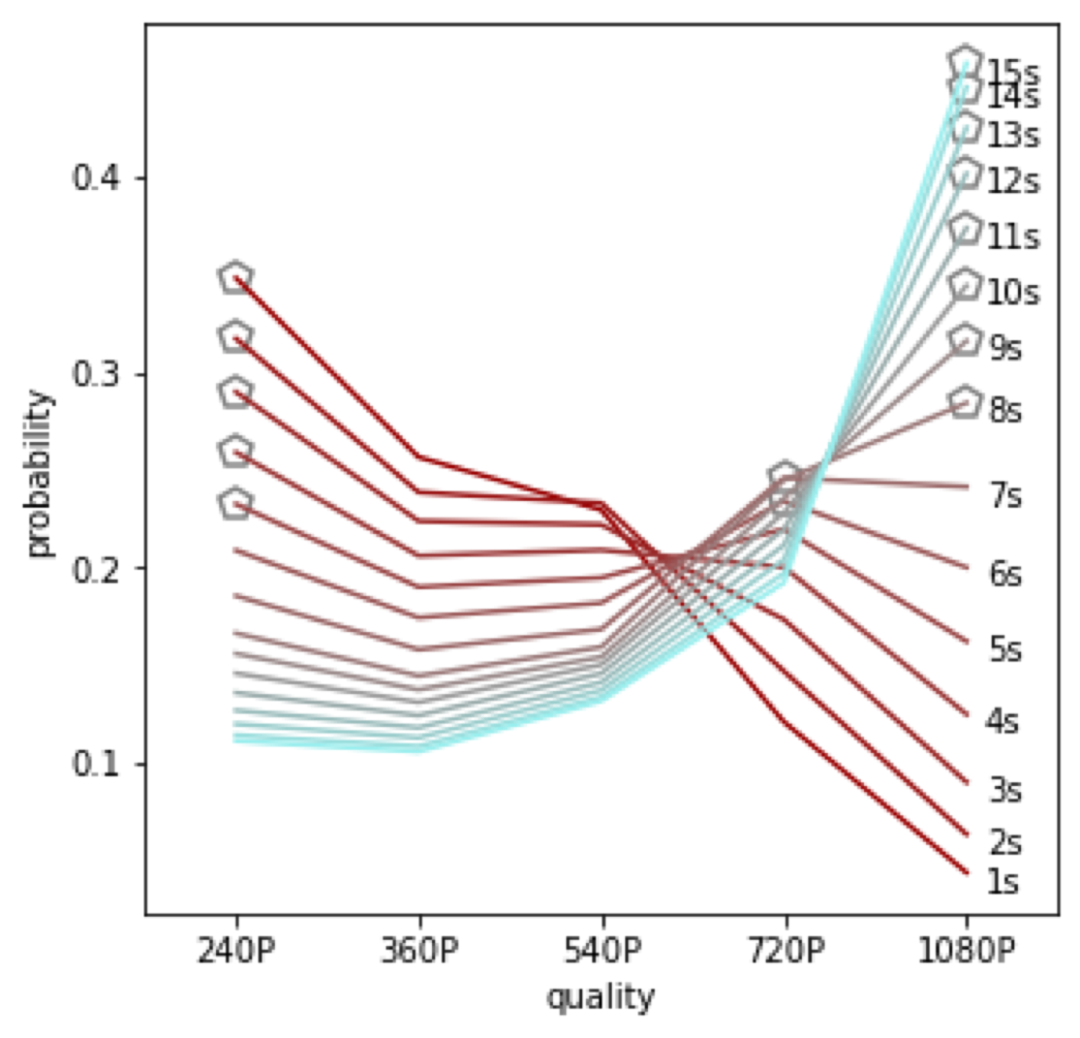
图5: Mimir 在不同剩余缓冲区大小下切换码率的概率
Mimir成功的关键在于预测未来的吞吐量和下载时间。Mimir掌握的关于当前会话的信息越多,如:手机或有线电视、手机数据类型(4G、5G等)、农村或城市、一天或一周中的时间等等,它在吞吐量估计方面就会表现越好。如前所述,吞吐量估计在视频刚启动时是很难预测的。为了在会话开始之前提供对吞吐量的良好估计,我们存储了一个包含世界上2万个地理位置的哈希表,以及它们在Vimeo上显示的平均值、标准差和95%的吞吐量(如图6)。该模型将字符串作为输入,并在运行时查找吞吐量。此表会定期更新,以跟上全球网络最新的变化。对于数据很少或没有数据的区域,模型会加载一个空字符串作为其输入并返回一个默认行为。例如,美国纽约的平均网络吞吐量和95%吞吐量分别是美国阿伯茨福德(Abbotsford)的324%和436%。正因如此,Mimir开始在阿伯茨福德地区采取不那么激进的策略。
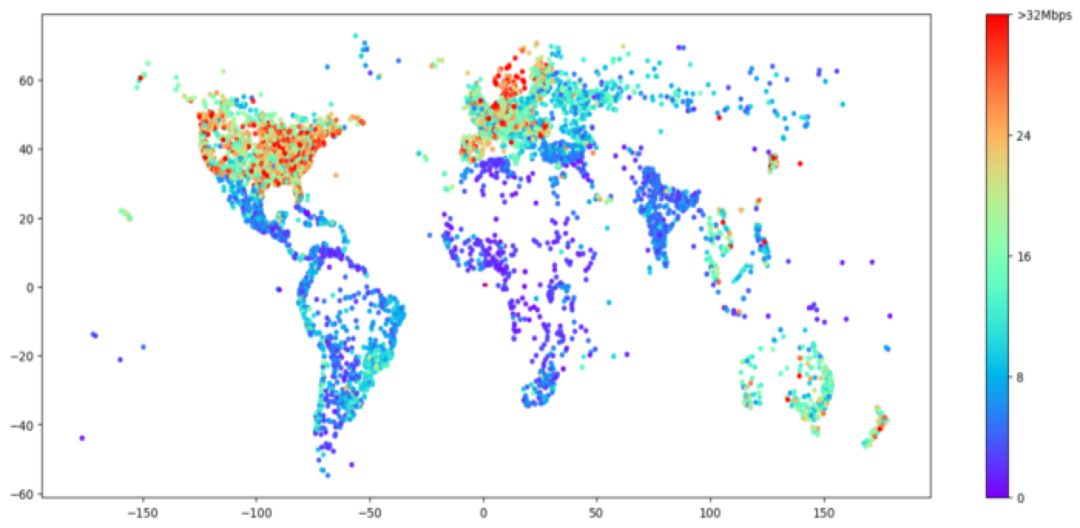
图6:按城市划分的Vimeo播放器平均网络吞吐量(2020 年 8 月至 11 月)。缺失区域的播放会话太少,我们无法很好地估计吞吐量。一般来说,发达国家的高密度城市中心的平均吞吐量超过20Mbps(想想 4G),足以传输1080p的视频。在更多的农村地区,即使在同一个国家,吞吐量也会下降到每秒几兆字节。请记住,Vimeo的流媒体速度取决于我们的CDN以及其他因素,因此该图并不反映平均本地带宽。
当我们为一个视频切片发送HTTP请求时,总的下载时间(dT)由两部分组成:首字节时间(time-to-first-byte,TTFB)和下载时间(dt),dt由视频切片大小(size)除以吞吐量(throughout)得到。TTFB取决于用户的网络状况以及该视频段最近是否已缓存在CDN中。值得注意的是,TTFB与视频切片大小无关。模型将TTFB与下载时间分开是很重要的。
假设我们只为模型提供总下载时间(dT)作为输入。该模型可能会假设:
dT = size / throughput + error
然而,如果我们同时提供TTFB和下载时间(dt)作为输入:
dT = TTFB + dt = TTFB + size / throughput + error
当平均TTFB远大于dt时,例如该视频未缓存在CDN上时,第一个模型会导致吞吐量估计出现较大偏差。假设对于某个视频切片,TTFB等于60 ms,dt等于30 ms,视频切片大小为 500 KB。这两个模型的吞吐量估计值分别为:
throughput = size / dt = 500 / 30 = 16.67 KB/ms
throughput = size / dT = 500 / (600 + 30) = 0.79 KB/ms
第一个是实际吞吐量,第二个是agent所认为的吞吐量(如果没有给出单独的TTFB和下载时间)。一个是4K画质,另一个则是540p!因此,在模拟和部署中分离TTFB和下载时间是很重要的。
在实践中,我们收集了数十万条吞吐量和TTFB trace数据,我们在随机采样的TTFB和吞吐量trace数据环境中启动每个播放会话。
平衡数据,这是机器学习中一个经典而又永恒的话题。我们通过从Vimeo平台的10万个真实视频流会话中随机采集的吞吐量数据和3万个视频数据来进行训练。由此产生的Mimir模型可以处理常见的吞吐量范围,但在切换到高质量(2K、4K)或处理低吞吐量会话(低于240p,意味着永久重新缓冲)时遇到了麻烦。我们意识到,需要训练Mimir处理各种吞吐量分布以及同样的每一次转码。
将2K和4K的视频添加到视频数据集并添加低吞吐量的数据有助于解决上述问题。我们的最终吞吐量数据采集策略从0.4~0.7 Mbps、0.7~2 Mbps、2~3 Mbps、3~4 Mbps、4~7 Mbps、7~20 Mbps 和 20+ Mbps 的数据集合中采集了相同数量的会话。这些范围分别对应于 240p、360p、540p、720p、1080p、1440p 和 2160p的码率,这是我们目前在Vimeo上使用到的有效的转码档位。
在之后的文章中,我还会继续给大家分享更多关于在线A/B测试中调试Mimir和将它部署到实际应用中的经验。
注释:
[1]https://arxiv.org/abs/1602.01783
[2]https://www.twitch.tv/videos/326113867?collection=u1vmyYMIYBXvlQ
致谢
本文已获得作者Fengjiao Peng授权翻译和发布,特此感谢。
原文链接:
https://medium.com/vimeo-engineering-blog/one-ai-streaming-videos-for-all-aeaedb8e5378
本文编辑:Alex
封面图 by Jackson So on Unsplash

@2017-2024 LiveVideoStack版权所有. 京ICP备20010033号-1  京公网安备 11010502042092号
京公网安备 11010502042092号







