
编者按
大模型AI席卷全球,推理创新的APP、场景落地越来越多。当训练达到一定阶段,推理必然会形成一个爆发。推理的产品要起来,必然要把推理的成本降到今天 1/ 10 甚至 1/100。此时该如何选好、用好 GPU ,进而影响推理成本?
最近, LiveVideoStack荣幸地邀请到PPIO的王闻宇老师接受采访。本文将从芯片怪兽英伟达公司垄断式增长和美国“卡脖子”2个热点问题出发。围绕过去、现在、未来三个时间线为大家梳理GPU的起源及其软硬件技术的更迭;同时,深度剖析GPU主流产品的参数和技术发展现状,并结合当前GPU的微架构设计,给出算力工程优化的几个思考和有效解决方案。
文/王闻宇
整理/LiveVideoStack
作者简介
PPIO派欧云的联合创始人和CTO王闻宇,2004年就开始做音视频,曾是PPTV 的联合创始人并担任首席架构师一职,主导了P2P、直播、点播、编码等一系列产品。PPTV被出售后,转投车联网公司智能支撑领域。2018年重回音视频领域创办PPIO派欧云,目标在于把对技术以及资源的理解打造成服务,并服务于整个音视频行业以及游戏领域与AI领域。

图:这是我的AIGC照片
00
前言:算力与GPU
算力,即计算能力(Computing Power)。更具体来说,算力是通过对信息数据进行处理,实现目标结果输出的计算能力。
最早的算力引擎。是人类的大脑,后来演变成草绳、石头、算筹(一种用于计算的小棍子)、算盘。到了20世纪40年代,世界上第一台数字式电子计算机ENIAC诞生,人类算力正式进入了数字电子时代。再后来,随着半导体技术的出现和发展,我们又进入了芯片时代,芯片成为了算力的主要载体。进入21世纪后,算力再次迎来了巨变,云计算技术出现,算力云化之后,数据中心成为了算力的主要载体。人类的算力规模,开始新的飞跃。
我们通常将目前负责输出算力的芯片,分为通用芯片和专用芯片。专用芯片,主要是指FPGA(可编程集成电路)和ASIC(专用集成电路)。像x86这样的CPU处理器芯片,就是通用芯片。它们能完成的算力任务是多样化的,灵活的,但是功耗更高。
游戏、数字货币挖矿、AI、科学计算等各方面都需要GPU,GPU成为了当下的关键问题。下面我就围绕GPU以及对算力整个行业的思考展开分享。
2023年两个事件的联想:
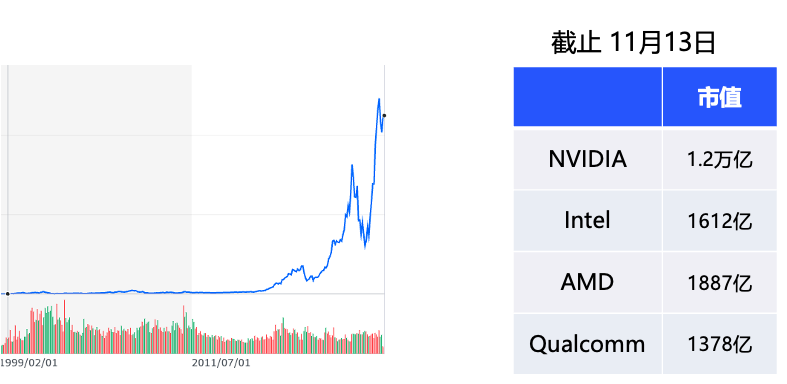
事件一:英伟达芯片怪兽一家独大!市值突破万亿美金
5月30日的时候,发生了一件重大的事情,5月30日美股交易时段,英伟达市值一天内暴涨超2000亿,冲破1万亿美元大关,英伟达的市值远大于Intel、AMD、高通,MTK的总和,甚至是其他公司的10倍;再看英伟达公司的PS、PE指标,可以看出综合情况是非常优秀的。
那么,英伟达芯片怪兽的地位是如何形成的?我在文章的最后会分析。
事件二:美国卡脖子问题再次升级!
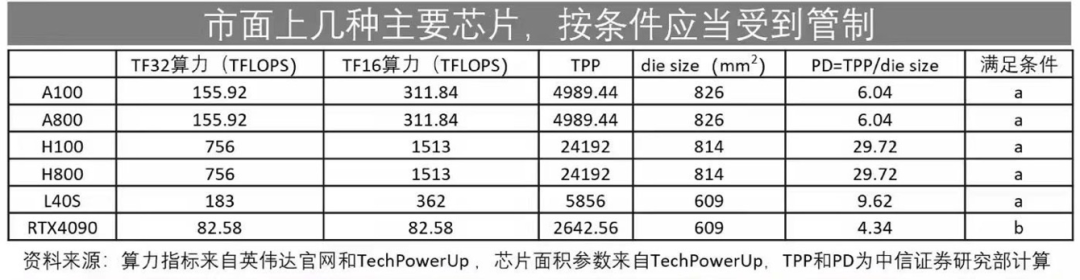
上图所示的卡型至少有一款是AI领域必备的卡型,但是令人遗憾的是,由于美国卡脖子问题再次升级,以上卡型全部被纳入禁售名单。
01
过去篇
1.1
为什么需要GPU?

CPU的定位是通用计算芯片,有强大的调度,管理,协调能力,应用范围广,灵活性最高,善于逻辑控制,串行的运算。
GPU的定位是并行计算芯片,主要是将其中非常复杂的数学和几何计算抽出,变成一个超高密度、能够并行计算的方式。最初专用于图形处理,后渐渐用于高密度通用计算,包括AI计算。
1.2
GPU的起源
GPU 的发展源于80年代,IBM是GPU理念的创始者,但它并未坚持。所以真正意义上的第一款GPU是英伟达在1999年发布的Geforce 256,并正式提出一个响亮的名字“Graphics Processing Unit”,这就是GPU的来源。从此之后,GPU一直高速发展。

图:这是第一款真正意义的GPU的照片
1.3
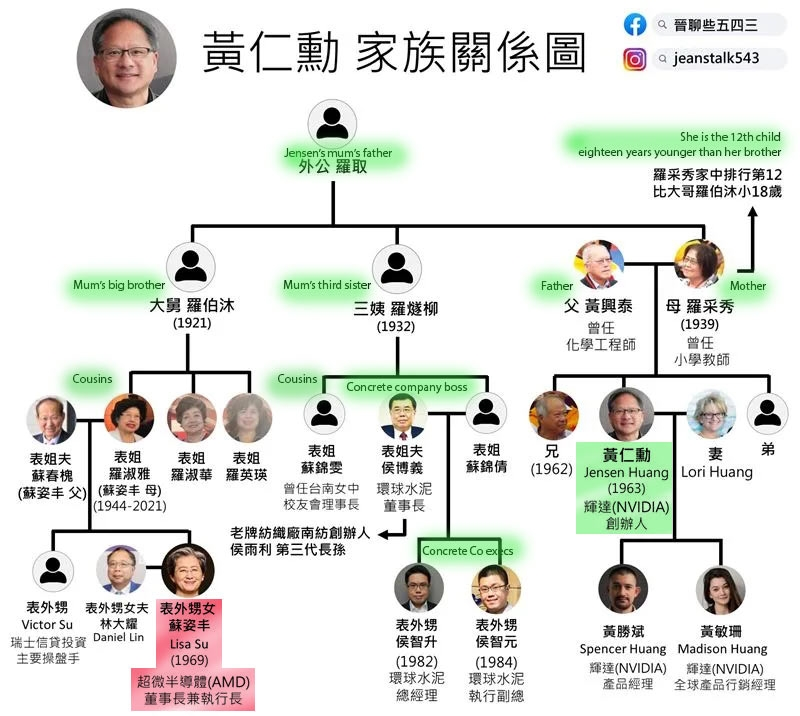
GPU的世界就是“两位华人之间的战争”
大家常说,GPU的世界就是“两位华人之间的战争”。英伟达的创始人黄仁勋是美籍华人,黄仁勋的外甥侄女苏姿丰是AMD的CEO。也就是说,英伟达与AMD两大巨头企业的CEO是亲戚关系,掌握了全世界最强大的两个GPU。如果再加上TSMC(台积电)也是华人,可以说华人主宰了尖端半导体行业的半壁江山。
这GPU公司的竞合历史:
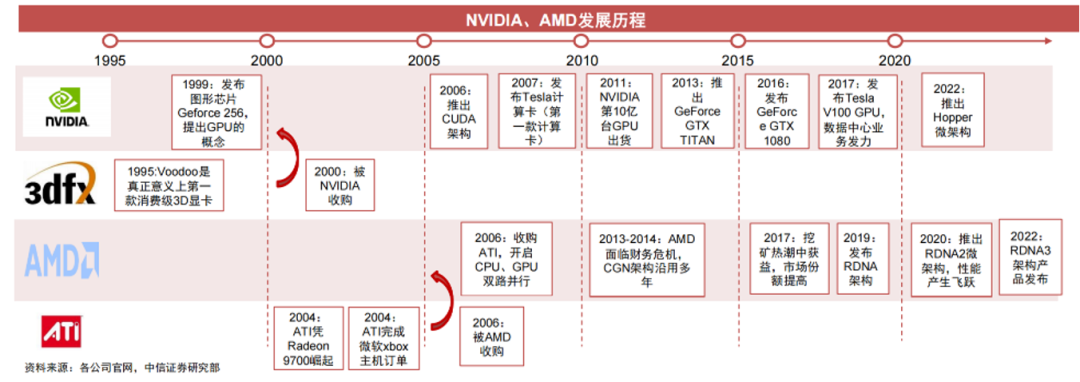
上图为GPU发展过程图,可以看出3dfx早期发展迅猛,2000年以不到一亿美金的估值被英伟达收购,ATI是AMD显卡的前身,2006年被AMD收购,所以后期基本为英伟达与AMD双雄争霸。
注意,这个图中似乎少了谁,就是著名的Intel。其实Intel在1998年发布了绝版独立显卡i740,在此之后的23年,就没有再发布过独立GPU,聚焦在做集成显卡,退出了GPU市场,现在看来,这不是明智的战略选择。直到2022年,Intel终于看到AI发展的趋势,才发布了新的独立显卡系列,这就是ARC系列。
GPU早期是为了用于图形渲染
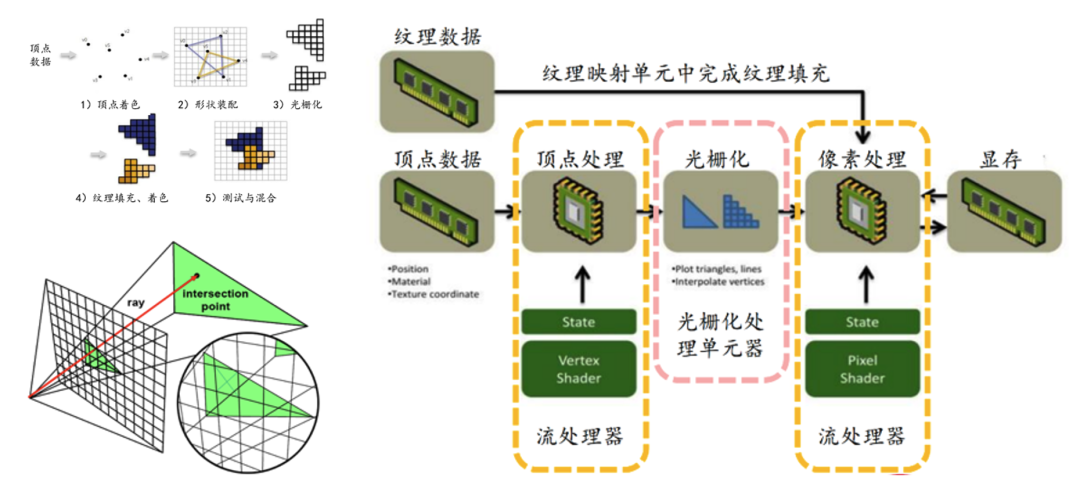
GPU早期一般为了3D渲染而设计。从计算机图形学的角度,GPU将三维事件的点阵通过矩阵变化投影到二维平面上,这个过程叫做光栅化,最终在显示器上结果。GPU的能力基本上是顶点处理、光栅化、像素处理等,这个过程包含大量的矩阵计算,刚好利用了GPU的并行性。
后来,GPU在设计上走向了通用计算。
2003年,GPGPU(General Purpose computing on GPU)的概念被首次提出来。GPU不再以图形的3D加速为唯一目的,而是能够用于任意并行的通用计算,例如科学计算、数据分析、基因、云游戏、AIGC等。
直到2009年英伟达首次推出Tesla系列后,GPGPU时代才真正来临。
目前国内有许多做GPU的公司,大部分都投入在GPGPU领域,这些公司都放弃了图形渲染,直接以高密度的并行计算作为发展方向。
以英伟达的产品来举例,有如下产品系列

第一个用于游戏领域,包括GeForce系列、RTX系列,我们常说的4090就是属于游戏领域的系列;常说的x0y0编号就是GeForce系列。
第二个用于数据中心领域,包括Tesla系列,常提到A100、H100就属于这一系列。英伟达有要求,不允许游戏领域中的GeForce系列进入数据中心。因此英伟达游戏系列的产品在同样芯片、同样算力的情况下,GeForce系列的价格要比Tesla系列低3~5倍。正因为价格相差太大,现在国内做大模型推理、StableDiffussion图形生成等都以4090作为首选的原因;
第三个是用于高端图形领域,包括Quadro系列;这款在工业领域用得多。
第四个是用于汽车领域。
GPU支撑与架构的不断优化
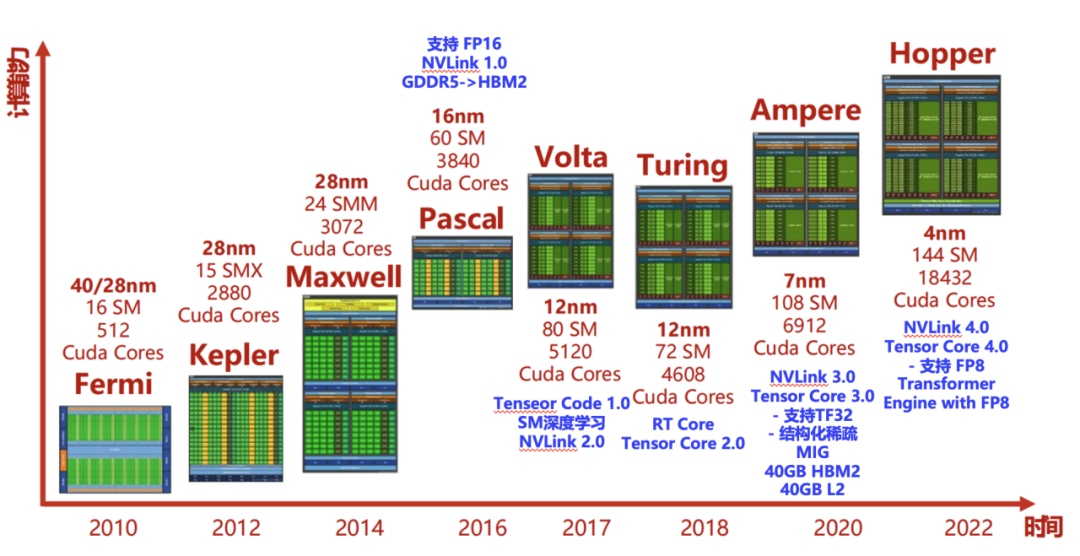
这是是英伟达的硬件架构变迁图。随着2007年英伟达推出 CUDA 1.0版本,使其旗下所有 GPU 芯片都适应 CUDA 架构:
CUDA生态和价格也是英伟达的最核心竞争力,也是英伟达万亿市值的关键因素之一。英伟达投入了一万以上的工程师在发展这个体系,基本上把人工智能里的大部分场景都做了深度优化。英伟达长期投入CUDA生态建设,为开发者服务,建立好了一系列的开源生态。

02
现在篇
2.1
先进的微架构设计
目前的GPU基本使用微架构设计,以最早的Fermi架构开始(2010年),那时候一个GPU是由4个GPC(图形处理簇 Graphics Processing Clusters)、16个SM(流多处理器,Stream Multiprocessors )以及512个CUDA Core(向量运行单元)组成的,这是GPU的特性。

其实图形渲染也是微架构的(以 2018年 Turing 微架构为例)
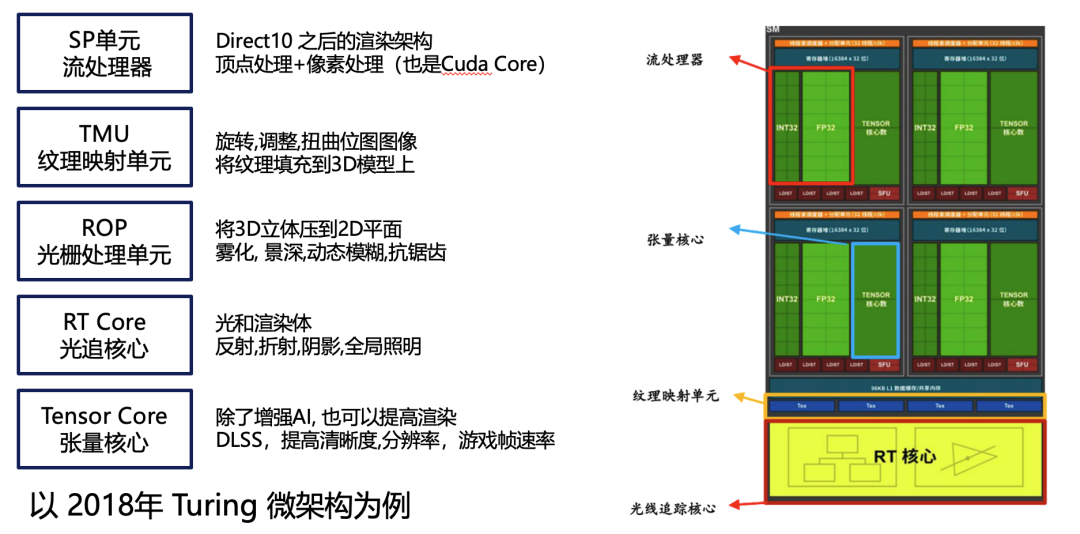
RT Core(RT核心)非常关键,实现了现代GPU中的光线最终效果。渲染效果中最重要的是光追,看这张光追低级效果和光追高级效果的对比图,差距非常明显,折射、反射、光影都呈现出很大的差距。

其实现在的手机GPU基本上都带有光追的效果和能力,但是手机的光追效果对比英伟达GeForce 40系列GPU的光追效果差距很大。一份最新的评测将英伟达 4070与高通GEN2进行对比,各个指标综合得出差距为25倍,即使用最好的手机也不可能体验到英伟达 4070渲染出来的效果。这也是云游戏成立的根本逻辑,让玩家在手机上也能体验到强大的GPU渲染所带来的的画质效果。
我们看看现在最新一代GPU的情况:
最新的 Ada Lovelace 架构(如Geforce RTX 4090)
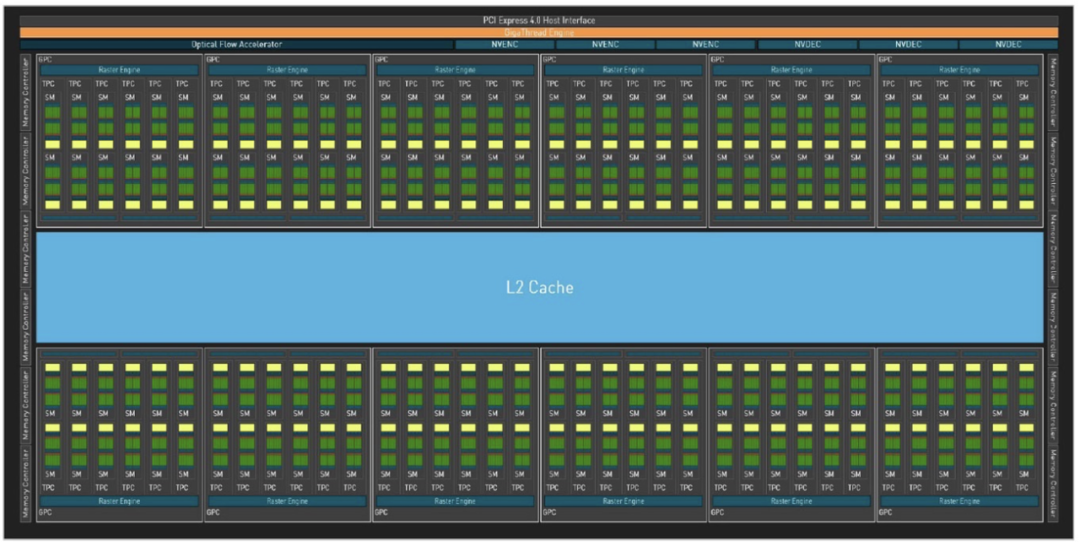
看看最新的Ada架构,也就是4090这一代,这是完整的管线图,密度相较于之前大大提高,仍然是微架构体系。
我们放大看看GPC:

我们再放大看看SM,是不是和前面Turing架构的SM很像:

另外,和Ada架构GeForce系列平行的是Hopper架构的Tesla系列,也就是传说中的H100/H800,这两个架构的管线大致是相同的,特别说明的是Tensor Core中的内容是完全一样的,所以在Ada架构的4090上也可以很好地发挥Hopper架构AI的特性。但Ada架构与Hopper架构最关键的区别,Ada不知道多卡高速互联,也就是NVLink/NVSwitch这套技术。
2.2
AI 计算中的浮点数
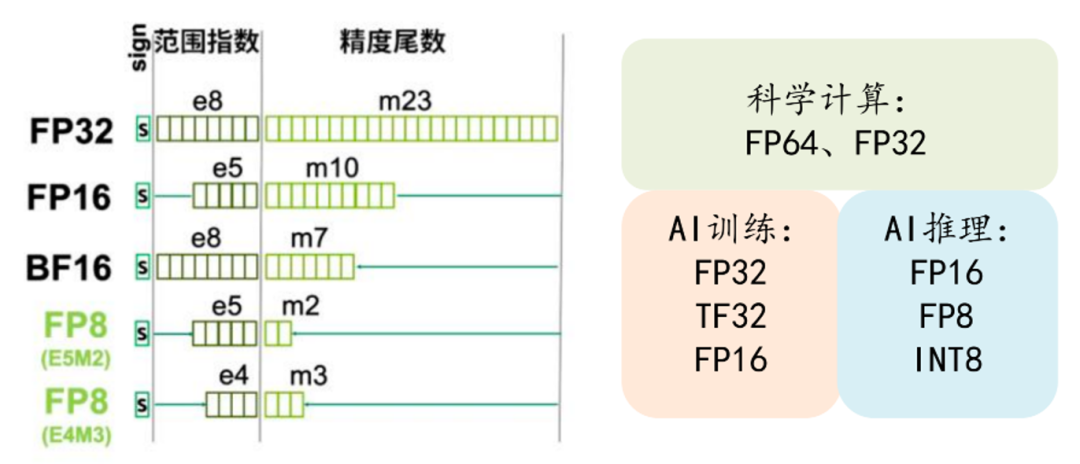
英伟达能够成为AI领域中的必选项的其中一个原因涉及到浮点数,浮点数在存储的时候由三个部分组成:符号位、指数位和尾数位。

浮点数的值可这样计算:
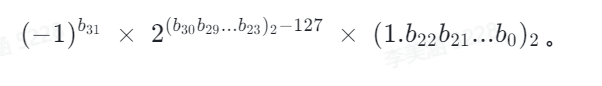
以 32 位的 float 为例,0.6 可以表示成

如下图,其中
●符号位是 0
●指数位是 01111110(126),表示 -1。(-1 偏移 127,即 126 - 127 = -1)
●尾数位是 1.00110011001100110011001,表示 1.1999999284744263。
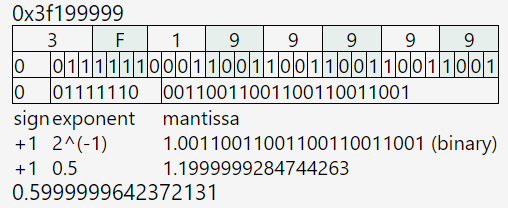
注意:尾数部分在实际存储时是将小数点前的 1 省略的;指数部分需要做一次偏移,-1加上 127 的偏移变成 126 再进行存储;最前面为符号位置,指的是这个数的正负,0 表示正数,1 表示负数。每个浮点数都是由符号位、指数位和尾数位所构成。

按照计算场景所要求数据精度和表示范围,可以选择不同的浮点数类型。常见的浮点数类型有 64 位的双精度 double(FP64)、32 位的单精度 float(FP32)、16 位的半精度 half、以及四分之一精度的 FP8 等。其中,半精度在指数位和尾数位的分配上又可以细分成:bf16 和 FP16。同样 FP8 也可以细分成 E5M2,E4M3。
那么在这么多浮点类型中该如何选择呢?
●一般来说更少位数的浮点数运算所需要的计算成本也更低,因此选用更小位数的浮点数有利于提升性能降低成本。
●但更少的位数也意味着数据的表示范围和精度的能力会降低,同时也要考虑表示范围和精度之间的平衡,否则会导致数据信息的损失,在推理场景下具体表现为推理的效果会变差。
●另外对于 FP8 这样的新类型,也只有最新的 GPU 硬件上才会支持,而新的硬件也往往比较昂贵。
因此,必须结合实际场景的性能要求、数据值分布以及硬件性价比等多个因素综合考虑才可以选择最佳的浮点类型。不同类型的浮点数在做不同硬件上处理时所带来的性能和成本效果是完全不同的。例如,科学计算往往使用 FP64 与 FP32,对应 C 语言中的 double 与 float。但是在 AI 领域中,特别是推理领域,精度不是最敏感的因素,同时数据的分布也表现为集中在 0 值附近,因此在 AI 领域,在不损失较大效果的前提下采用更少位数的浮点数类型是一个非常不错的优化方案。它可以使得计算量大大减少,提升性能,降低硬件成本。
2.3
CUDA Core 和 Tensor Core
关于 CUDA Core:
NVIDIA 率先在 GPU 中引入了通用计算能力,使得开发者能利用 CUDA 编程语言来驱动。这时候 GPU 的核都是CUDA Core。由于一个 GPU 里面有大量的 CUDA Core,使得并行度高的程序获得了极大的并行加速。但是,CUDA Core 在一个时钟周期只能完成一个操作,类似上面的矩阵乘法操作依然需要耗费大量的时间。

关于 Tensor Core:
GPU 最善于的做的“加乘运算”(GPU中有最常用的矩阵计算,就是先乘后加,也就是FMA)FMA:Z=W*X+b
NVIDIA 为了进一步加速“加乘运算”,在 2017 年推出了 Volta 架构的 GPU,从这个架构开始 Tensor Core被引入。它可以在一个时钟周期完成两个 4×4x4 半精度浮点矩阵的乘法(64 GEMM per clock)。

这是 Tensor Core 性能强劲的示意小视频,他将“加乘运算”并行化了。例如 Pascal 这一架构没有 Tensor Core 的能力,所以输出很慢;但在 Volta 架构中,引入了Tensor Core之后,能够以 12 倍的效率完成加乘的计算。

2.4
英伟达最近两代架构的特性
Ampere 架构
上一代是 Ampere 架构(2020年),采用的是 Tenser Core 3.0 。
其中著名 A100、A800、V100,以及游戏卡 Geforce RTX 3090 就是这个 Ampere 架构。
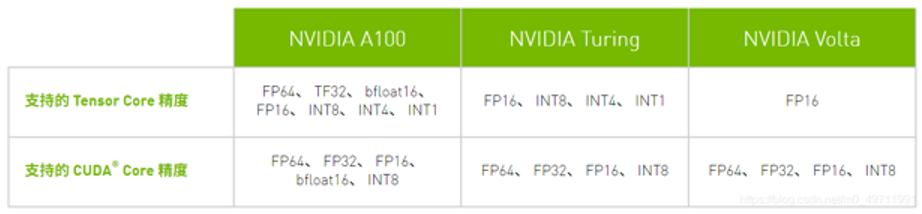
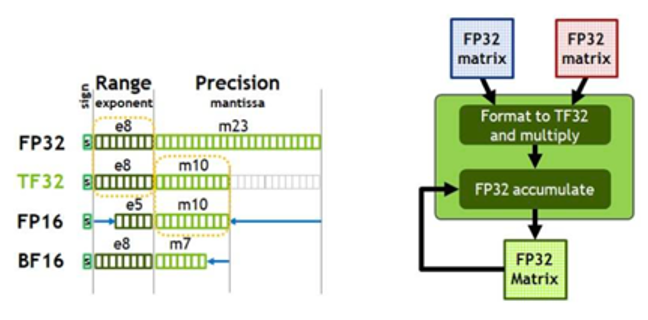
这代架构对比之前的 Turing 架构(2018年),其 Tensor Core 主要支持了三个新的数据类型,FP64,TF32,和BF16。其中 TF32 没有 32 位,只是阉割了精度尾数,只有 18 位,AI 行业中 TF32 用得并不广泛。但 BF16 就非常关键了,BF16 就是将 FP16 的指数位和精度位做了偏移,正是因为这个偏移使得 BF16 在 AI 训练的展示中范围大大扩大,所以 BF16 也是现在很多 AI 模型所训练的主流选择。
除此之外,还支持了结构化稀疏,稀疏矩阵是在矩阵中大量都为 0(或者接近于0),能够通过硬件快速计算出来的矩阵。Nvida 的 GPU 专门为稀疏矩阵做了优化,使得相同规模的稀疏矩阵的计算速度是稠密矩阵的 2 倍。
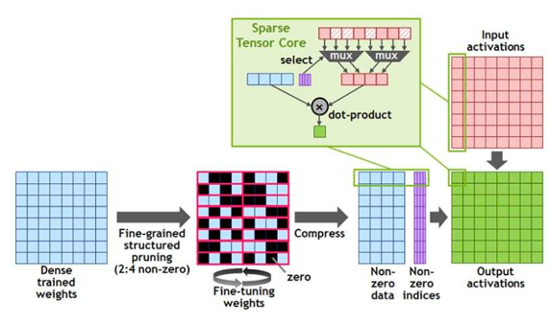
千万不要小看这两个特性,我认为这两个特性的支持大大提高了 OpenAI 的发展速度,使得 OpenAI 的 GPT3.5 能够提前一年出现。
Ada 架构和 Hopper 架构
这一代架构就是 Ada 架构和 Hopper 架构(2022年),采用的是 Tenser Core 4.0。
其中著名 H100, H800,就是这一代 Hopper 架构的典型代表,另外,著名的游戏卡 Geforce RTX 4090 就是这一代Ada 架构,他们都是用同样的 Tenser Core 4.0。
这代架构,最突破的变化是,Tenser Core 开始支持 FP8,就是将 FP16 又变小为 FP8,这是在AI领域中都要抢购4090 的原因。相较于 int8,FP8 能够相对容易地实现全链路量化,将其性能提高一倍,成本降低一倍,这是最为重要的一点。
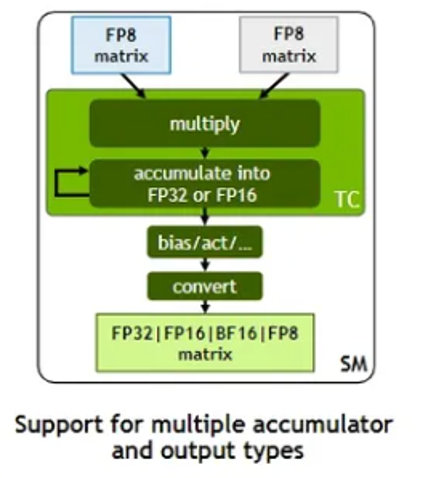
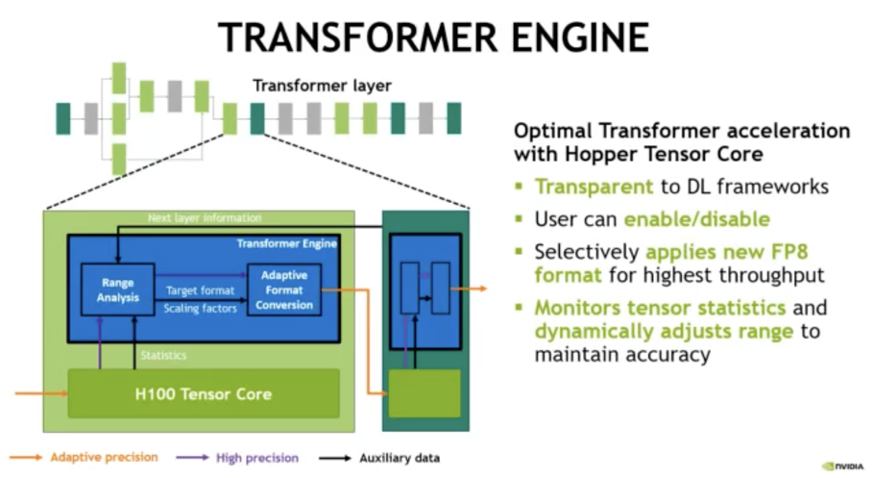
为了让开发者更方便地使用 fp8 来加速基于 Transformer 的模型,Nvidia 发布了 Transformer Engine (TE)。
Transformer Engine (TE) 是一个用于在 NVIDIA GPU 上加速 Transformer 模型的库,包括在 Hopper GPU 上使用 8 位浮点(FP8)精度,在训练和推断中提供更好的性能和更低的内存利用率。TE 为主流的 Transformer 架构提供了一系列高度优化的构建块,以及一个类似于自动混合精度的 API,可以与特定框架的代码无缝集成使用。TE 还包括一个与框架无关的 C++ API,可以与其他深度学习库集成,以实现 Transformer 的 FP8 支持。
这样一来,对于大预言模型的开发者就无需手动写底层基于 tensor core 的算子来使用 fp8 这个新特性,而是可以直接调用 TE 的 API 来组合出 LLM 的推理引擎,极大地简化了开发者的工作量。
2.5
关于FP8 量化带来了很好的效果
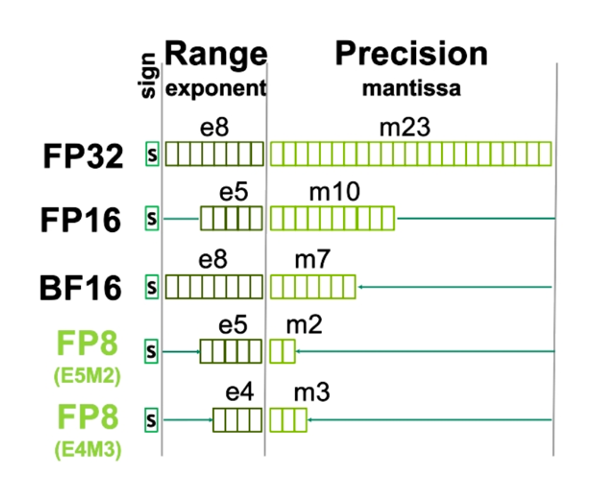
首先,说说什么是 FP8,以及 E5M2,E4M3?
FP8 是 FP16 的衍生产物,跟 FP16 类似,只是 FP8 总共使用 8 个比特位来表示一个浮点数。它包含两种编码格式E4M3 与 E5M2。
●对于 E4M3 而言,其包含 4 个指数位、3 个尾数位、以及 1 个符号位。
●E5M2 同理,其包含 5 个指数位、2 个尾数位、以及 1 个符号位。
可见,E4M3 与 E5M2 只是在指数位和尾数位上所分配的尾数有所差别而已。很显然 E4M3 的表示范围要比 E5M2 大,但 E4M3 的精度上不如 E5M2。
然后,我们看一下用 FP8 来代替 FP16/BF16 的效果怎么样?
可以先回顾一下 FP8 的特性点:
●FP8 的指数位和尾数位相较于 FP16/BF16 都会少一些,精度和表示范围的能力上相较于 FP16/BF16 会有所降低;
●但 FP8 的总位数只有 FP16/BF16 的一半,因此计算速度会更快,所需要的显存资源也更少。
由此可以得出这样一个结论:在对于数值表示范围不大且精度要求不高的场景下,用 FP8 代替 FP16/BF16 是完全可行的。
接下来我们再看一组实际的实验数据:
下面的图来自于一篇论文,作者将在 AI 训练场景下将 FP8 与 FP16/BF16 进行了对比。其中,
●横坐标是训练的进度;
●纵坐标是损失函数的值,这个值约低越好;
●浅色实线表示的是 FP16/BF16 的训练效果,而深色的虚线表示的是 FP8 的训练效果;
●作者用不同的颜色表示126M、1.3B、5B、22B、175B 不同规格的模型。
我们可以看到同一规模的模型下,深色虚线与浅色实线的两条曲线几乎完全重合,这意味着用 FP8 量化的效果和用 FP16/BF16 基本相同。

因此,假如把 FP8 来代替 FP16/BF16,训练和推理的性能至少可以提高一倍,而且效果上没有差异。
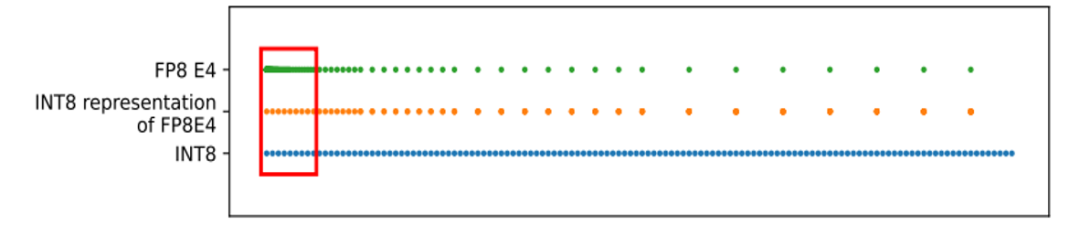
最后,我们再来看一下 FP8 的量化与 INT8 量化相比有什么优势?
这是 FP8 和 INT8 的值分布情况:
不难看出,
●FP8 的值分布呈现非均匀分布,它在绝对值较小的区域比较密集,而在绝对值较大的区域表现为稀疏;
●而 INT8 的值是完全均匀的;
●另外,如果用 INT8 来表示 FP8 的话,会在绝对值较小的区域产生较大损失,而在绝对值较大的区域表现良好。
综上所述,对于 0 值附近分布比较稠密,距离 0 值较远的数据比较稀疏的这种数据分布来说,FP8 是最好的。而 AI 领域的模型权重恰恰大概率符合这一特性,因此,用 FP8 来进行量化会比 INT8 的损失要更少。
下图是一个 FP8 和 INT8 量化后效果的具体对比,可以看出原数据经过 INT8 量化后许多 -0.1、-0.001 的数据都被量化为 0 了,但用 FP8 量化时,无论是 E5M2、E4M3,这些较少数值的数据基本都被很好地保留了。

上面我们只是理论上说明了 FP8 对于 0 值附近的数值具有很好的精度保留能力。但实际推理过程中激活值真的是在 0 值附近分布得更加稠密吗?
有学者针对这一问题专门做了验证,如下图,他把模型推理过程中的激活值都提取了出来,分别在第2层、第12层、第24层做了采样。我们可以看到无论是在 attention 阶段还是在 FFN 阶段,各个模型层的激活值都有显著的近似正态分布的性质(当然这里面也会有一些极少量的离群值,这些值可以在具体的量化方案中做特殊的处理)。
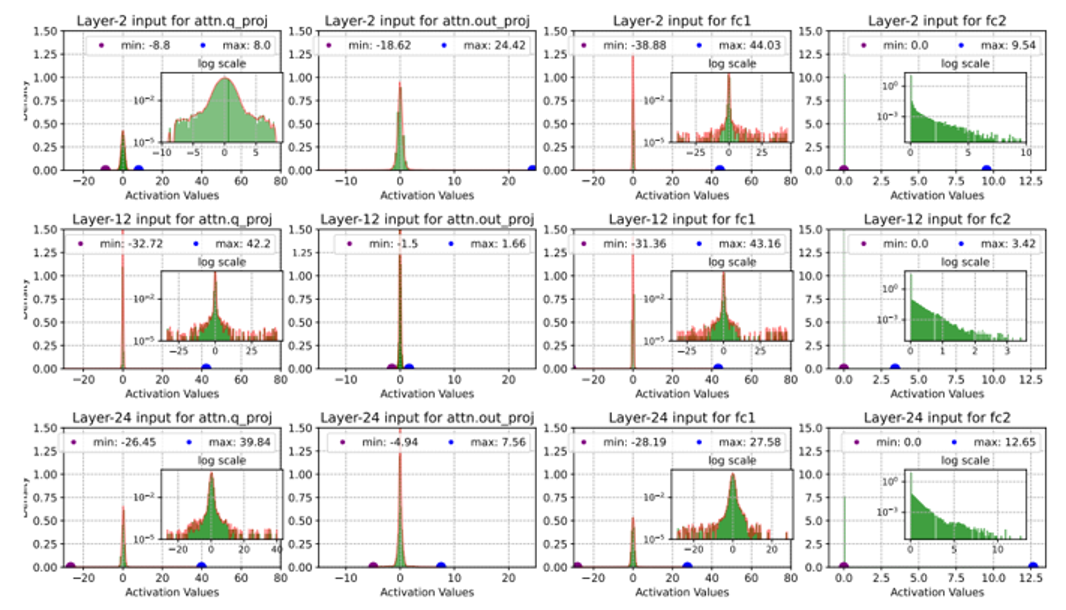
激活值在 0 分布较为稠密的特性,正符合了 FP8 的表现能力,这就是 FP8 逐渐成为大家做 AI 的主流的原因,也是 Ada/Hoper 架构受欢迎的主要原因之一。
在 Ampere 架构时代,很多人用 INT8 量化,但在 Ada/Hopper 架构时代,INT8 量化的效果远没有 FP8 好。
因此,在 Ada/Hopper 架构上应该优先使用 FP8 量化而非 INT8 量化,因为 FP8 具有 INT8 级别的性能的同时,又减少了量化带来的数据精度损失。
2.6
说说稀疏化加速(HyperAttention)
再谈谈稀疏化的加速。稀疏化是什么?图上示意的是一个矩阵,矩阵中有很多0,它会通过行和列之间的交换,最终把数据密度高的地方,拉到这条反斜线。后面无论是加还是乘,都能很快计算出来。

要把左侧中的第一个图变为第三个图,首先要变为第二个图,凡是黑框以内的数据保留,剩余的全部归零,也就是把一些比较暗的线都剪掉了。在处理大矩阵时效率很低,在处理第二个图的矩阵时效率则非常高。这就是一种常见的方案,叫剪枝。


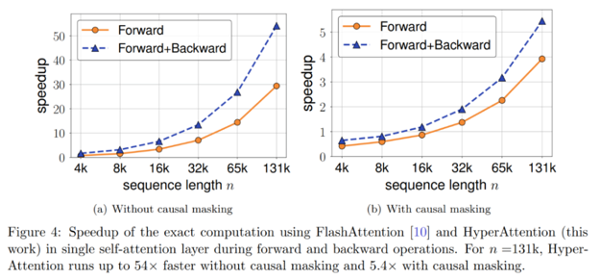
剪枝能够很好用于长序列长度模型,当序列的上下文特别大时,剪枝的效果会非常明显。
图中的forward属于推理,forward+backward属于训练。可以简单理解,随着上下文越长,剪枝效果越好。如果是因果论的模型(例如laMa模型),在很长的参数下会有20倍的差异,但是在非因果论的模型(例如GM模型),优势会少一些。大家可能见到过一个模型能支持很长的上下文,能够把《哈利波特》一本书读下去,其实并不难,只要用剪枝就能做出一定的效果。
2.7
说说投机采样
投机采样(Speculative Decoding)是 Google 和 DeepMind 在 2022 年同时发现的大模型推理加速方法。它可以在不损失生成效果前提下,获得 3x 以上的加速比。GPT-4 泄密报告也提到 OpenAI 线上模型推理使用了它。虽然OpenAI 的具体方法保持保密,但谷歌团队已经将其研究成果公之于众,并入选 ICML 2023 Oral。这项技术很有可能可能成为未来大型模型推理的标配。
投机采样是一种创造性的工程化加速方法,它与算子融合、模型量化等方法完全是不同维度的。
其核心是,用一个比原模型小很多的草稿模型(draft model),来加速原模型的推理。草稿模型一般都会比原模型小很多倍,因此推理速度也是比原模型更快,消耗资源更少,但它有一个缺点,就是推理生产的 token 可能是不对的。
那怎么解决这个问题呢?很简单,解决方案是先让小的草稿模型推理若干的 token,然后再将这些 token 让大模型检验其是否合理。如果合理则继续让小模型接着推理,否则就大模型自行推理。
由于大模型检验小模型的推理结果是可以并行地检查多个 token 的,因此这个过程要比大模型自己一个一个的推 token 要快很多。这也就意味着,只要小模型在多数情况下的推理是正确的,那么整个的推理速度就会很快。
用一个比喻来形容的话,有点像一个教授带着研究生做课题,课题中的一些研究任务直接就交给研究生完成了,但教授会对这些任务的完成情况进行检验,如果有错误教授会再做出修正,这样老师和学生相互配合,这个科研的效率就提升了很多。
目前一些推理框架已经开始支持 投机采样了,如 llama.cpp。也有一些开源模型直接同时提供了原模型和草稿模型,如:Chinese-LLaMA-Alpaca-2。
llama.cpp 的作者 gg 实测,通过投机采样可以提升至原来 2 倍的推理速度。
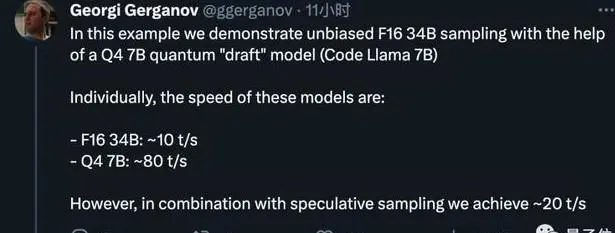
2.8
关于多卡互联的评测数据
多卡协同是英伟达显卡系列的关键:

多卡协同也是当今发展的关键。图上列出了NV测试库里的第二代、第三代、第四代的动画协同技术,可以发现,不同的架构一直在升级,从 Volta 到 Ampere 到 Hopper,总带宽数和 GPU 最大链路数都有所增加。
NVLink 主要用于两卡甚至四卡间的交替互联,但是卡多后则无法使用 NVLink,要用 NVSwitch。
第二个图就是 NVSwtich 的数据,因为它在训练时数据非常大,一个卡的数据存不下来,就必须用卡间通信,卡间带宽是多卡互联技术在大模型训练时会遇到的非常大的瓶颈。
为什么 4090 是性价比最好的推理显卡?
●相较于 H800 商用卡,消费级卡 4090 具有极高的性价比优势;
●相较于 不支持 fp8 的 3090/A800 来说,4090 又支持 fp8 这一新特性;
●在 40 系的同代卡中,4090 的显存又是最大的,性能最高的;
●8 卡 4090 的整机基本上可以满足未量化 70B 级别的大模型推理。
因此综合来说,对于 fp8 有强需求的推理场景,4090 是各种因素平衡下最佳的选择。
03
未来篇:趋势思考
3.1
说说 H100 比 A100 强在哪儿?
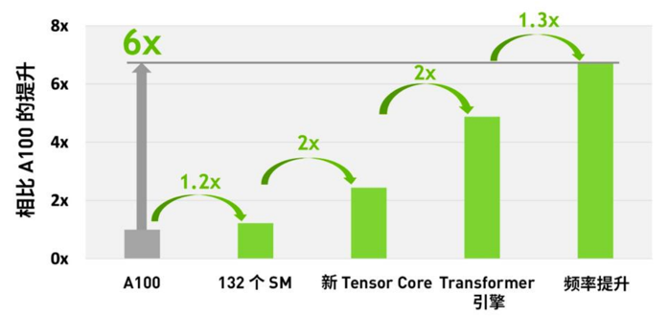
H100比A100强不是因为密度提升,其实就密度本省只有1.2倍的提升;更多是因为微架构的设计。新的Tensor Core提升了2倍,新的Transformer引擎提升了2倍,频率提升1.3倍,总计提升了6倍(在大模型下表现)。因此英伟达的性能不是纯靠密度提升的,是通过架构优化进行的提升。
未来的H200和B100,性能还会有指数性的上升。
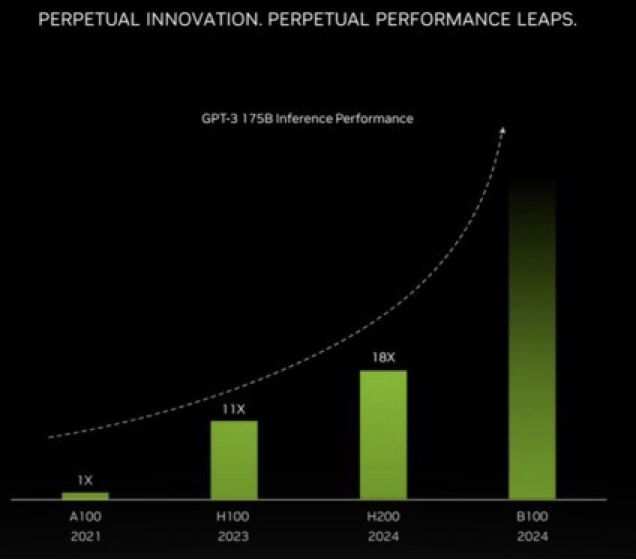
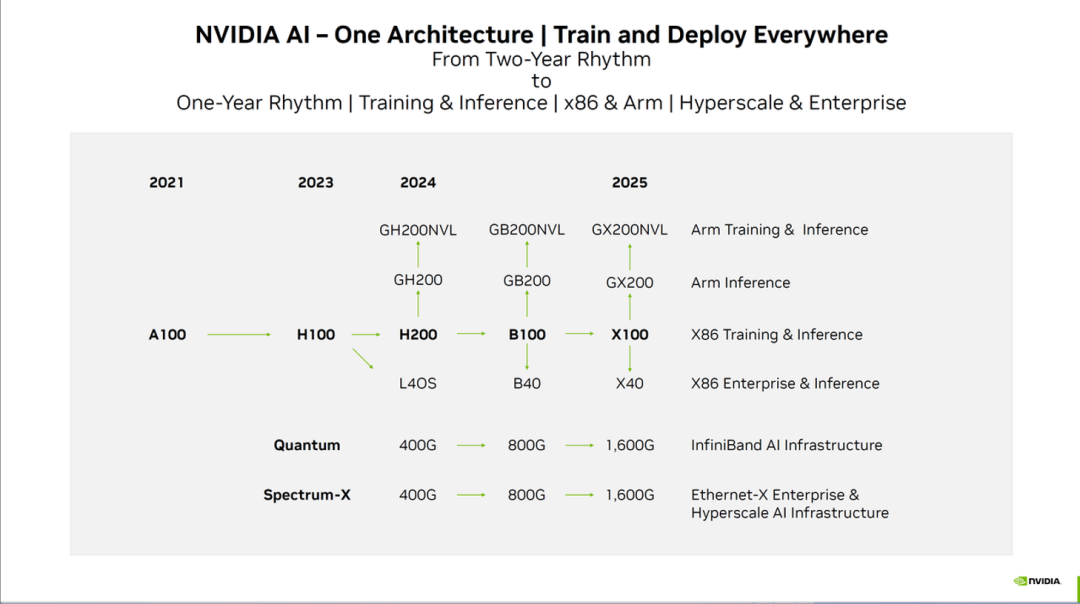
这是英伟达未来大致的新GPU路线图:
3.2
CPU 和 GPU的二合一可能也是新的方向
未来还有一个可能的趋势是CPU和GPU二合一。例如AMD的MI300,基本是直接把GPU和CPU合在一起。也有人选择,苹果的M2Ultra,因为它拥有很大内存,显存带宽也差不多。
AMD的 Instinct MI300系列。如MI300A,24盒Zen4架构CPU,CDNA3架构GPU,128GB HBM3内存,5.2T显存带宽。

还有苹果的Apple M2 Ultra系列。

3.3
还有一种 GPU 的变种 ==> IPU
2022年6月,MLPerf(全球最权威的AI计算竞赛) Graphcore 的 IPU ( Intelligence Processing Unit)打败了当时的王者NVIDA 的 A100,除此之前,还有其他说法,如Google 提出的TPU ( Tensor Processing Unit),还有NPU (Nerual Processing Unit),可以理解他们是类似的,在某些特定的 AI 和 ML 任务中有出色的表现。
那么,IPU未来会取代GPU的位置吗?

IPU虽然近几年在高速发展,但在我看来,不可能取代GUP的位置,因为它们擅长的不一样。CPU擅长的是控制和复杂运算,GPU擅长的是各种高密度的通用的计算,IPU更擅长处理某个特定的AI任务和推理,因此这三者未来应该是有效结合的关系。可能未来CPU:GPU:IPU的使用量是1:8:1。
3.4
“卡脖子”问题
2022年8月31日:美国政府通知 英伟达 和 AMD,分别限制中国出口 A100、H100、MI250AI 芯片。
之后英伟达针对2022年的禁令,推出了降低参数配置的阉割卡,也就著名的A800,H800,主要降低了卡间通行速率,和浮点算力 (FP64,FP32)。
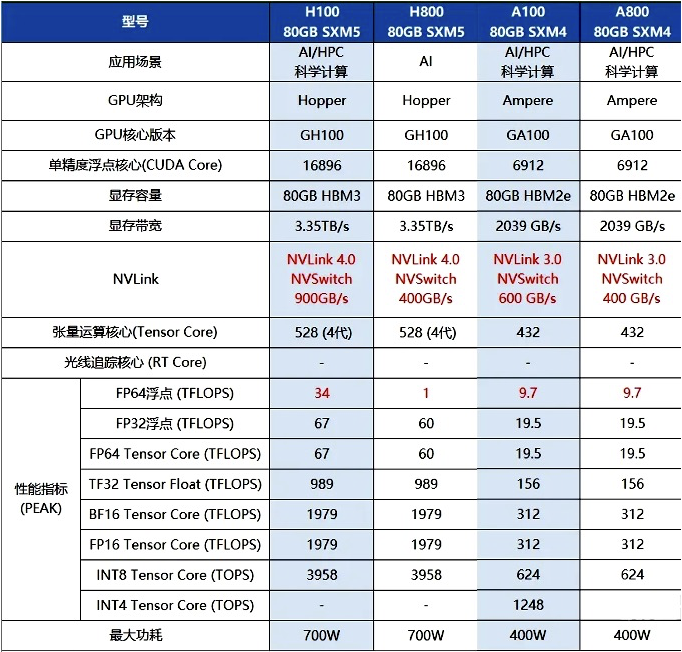
卡间通讯对大模型训练来说,非常关键,这样大大限制了训练的效率。
2023年10月17日,是美国商务部的新一轮限制,这次除了 A100、 H100,还限制了 A800、H800、L40s,甚至游戏卡 RTX4090 也不例外。
但和上次一样,英伟达很快推出了“特供卡” ,HGX、H20、 L20、L 2 (这些卡均不能卡间通讯),性能大受影响不到之前的 H100 的20%。
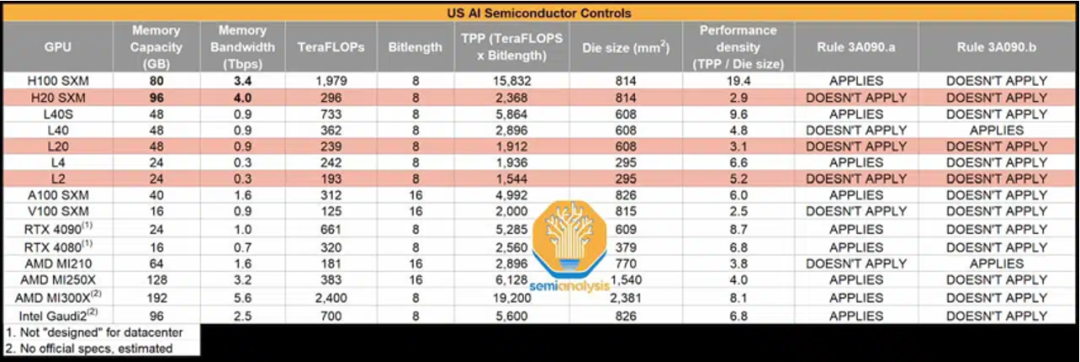
那么我们中国公司应该怎么应对“卡脖子”呢,大概有几个路径吧
●第一:买不到卡,慢慢训练,时间变长
●第二:走完全不同的技术路线,发展“小模型”发展量化,用低端卡(甚至比GeForce RTX4090还要低的)来训练
●第三:还有就是在国外用公开数据集训练,在国内用私有数据集Fine-Tuning。
还有就是用举国之力解决“卡脖子”问题。其实芯片设计能力其实不是最关键的瓶颈,FAB厂和光刻机才是最关键的问题。
大家千万不要认为瓶颈只有光刻机,其实FAB厂也是瓶颈。FAB厂流程很多,包括硅晶圆的制备、光刻、蚀刻、沉积、掺杂、金属互联、钝化、测试和封装等。
要做一个先进的FAB厂其实非常难,要建设一个先进的FAB厂,需要投入至少150亿美金。
TSMC(台积电)之所以能占据很大的市场比例,关键是他们7nm以下的良品率做得非常高,背后很大的原因是TSMC养了上百位顶级的化学家、材料学家和生物学家来研发和解决问题。
这是FAB厂的目前能做到的能力表:
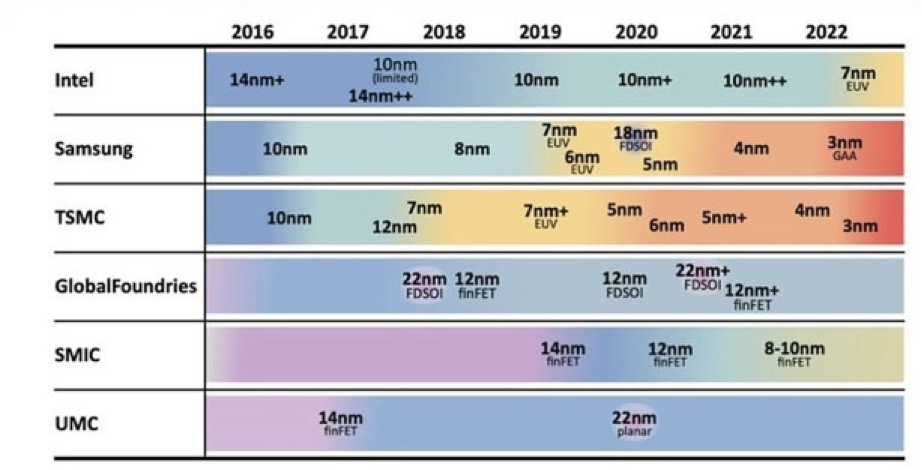
有消息称,2024年TSMC的3nm/4nm的芯片产能,基本被英伟达,苹果和高通包完了,他们3大巨头的芯片产能,也要看TSMC是怎么分量的。
除了FAB厂之外,最最关键的瓶颈就是光刻机了,可以看见,ASML占据了先进光刻机的绝大部分市场。特别是EUV技术(极紫外光刻技术),目前只有ASML能做到,只有这个技术,才能光刻出10nm以下制程的芯片。

不用光刻技术的对照表:

那么,中国的国产光刻机做得最好的是上海微电子,他们目前最先进的技术是ArF(氟化氩技术),能做出最高精度也只有90nm(相当于ASML在10年前的技术),因此光刻之路漫漫虽远兮。

也有人说中国没有,没不能想办法从国外“偷”一台EUV的ASML技术不就行了。我看这太天真了,这种关键技术就别想了。
ASML的EUV我了解需要至少5架波音747装满才能把零件装完。除此之外,ASML的光刻机是需要云端激活的,每次安装和变动的时候,
ASML会派人来调试,标记好地理位置,关键核心部件和系统都是通过互联网远程激活的。如果后续ASML发现GPS位置变了,关键核心部件和系统会直接远程云端锁定,用不了。
所以我们要解决这个问题,只有老老实实自力更新,自己攻克EUV光刻技术。
04
关于PPIO派欧云
PPIO派欧云的定位主要是做分布式云,怎么理解PPIO的分布式云呢?
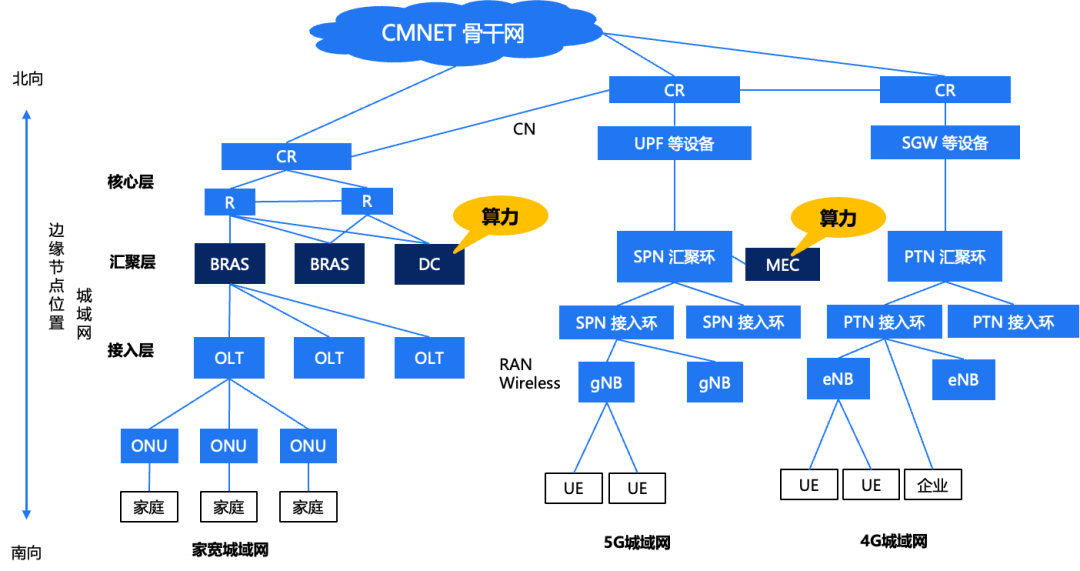
首先从骨干网角度看,图中标记了“算力”的就是PPIO分布式算力的部署位置,PPIO把算力部署在一些骨干网的大型节点、地市级的IDC甚至小IDC。

其次从城域网角度看,这是运营商北向-南向的图,PPIO也把算力部署在了汇聚层的DC。左边的图是固网,右边是移动网,在移动网中算力部署在MEC。
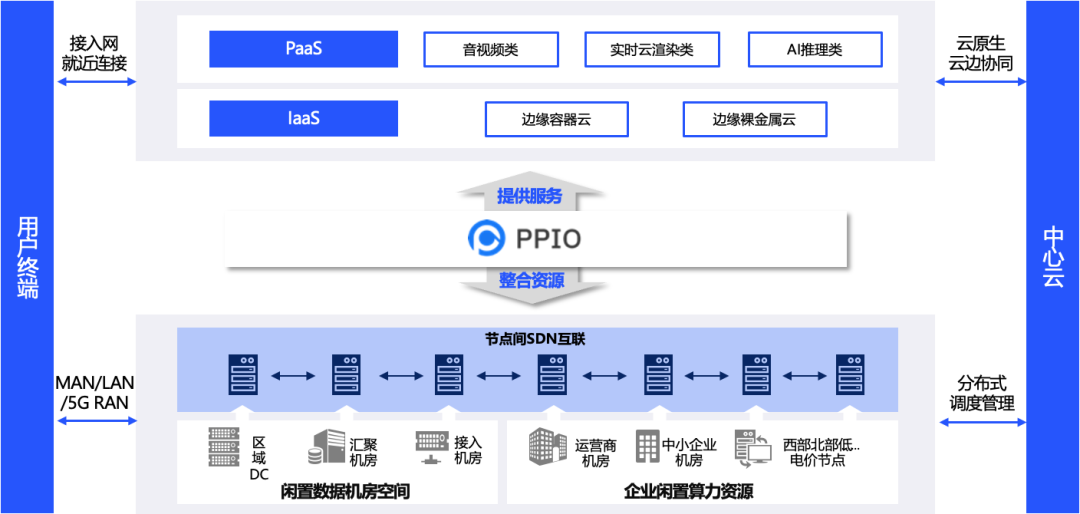
PPIO派欧云的产品架构如图,通过自建和招募的方式,把很多资源集成起来,建立好自己的软件服务,在此之上建立IaaS和PaaS的服务。PPIO派欧云主要覆盖的领域是音视频(CDN/泛CDN)、实时云渲染(包括云游戏)、AI推理,AI小模型的训练场景。
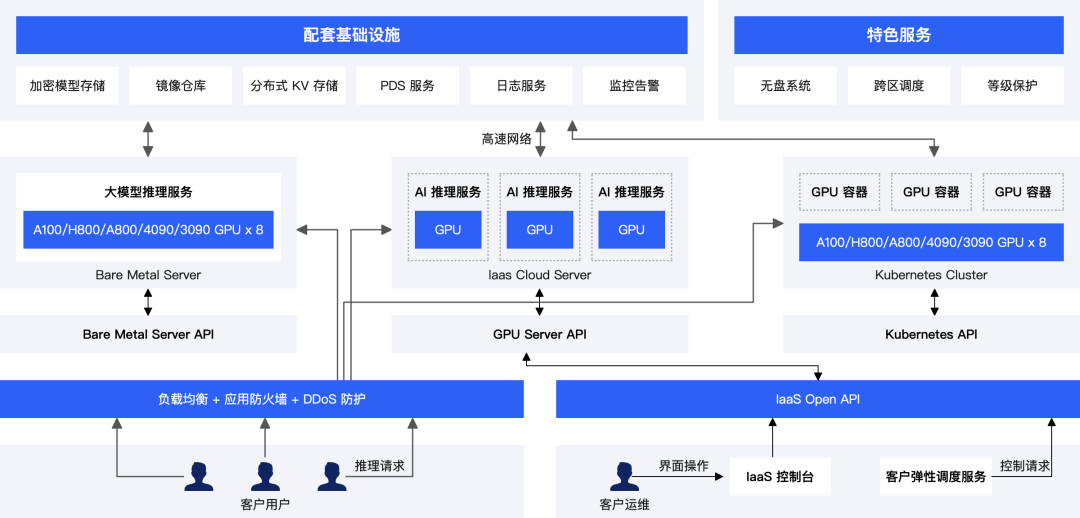
这是 PPIO 的 AI 算力 IaaS 产品如下:
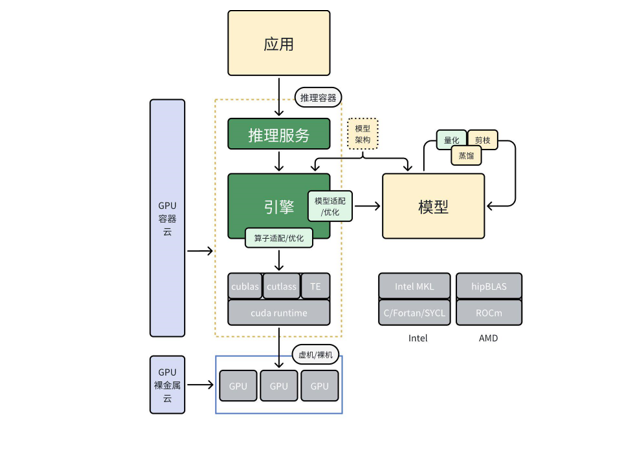
我们开发了具有核心云功能的 AI 算力平台,对外提供 GPU 裸金属,GPU 服务器,GPU容器三种形态的算力资源,以满足不同的 AI 算力场景。
此外,我们也为客户提供负载均衡、应用防火墙和DDoS防火等线上业务上必须的核心功能。为了方便客户使用算力资源,我们不仅开发了基于界面的控制台,也提供了开放 API 供客户进行二次开发和系统集成。通过这个 API 客户可以很方便地控制GPU 裸金属,GPU 服务器,GPU容器三种资源。
另外,我们也提供了无盘系统,跨区服务等特色服务,也可以协助客户过等级保护。
PPIO派欧云,除了提供算力IaaS产品,还能提供 MLOps(AI Infra)推理解决方案,帮助大模型公司实现算子优化、算子融合、量化,剪枝,蒸馏,投机采样等技术解决方案,从而做到推理加速。
在模型层,PPIO 具有丰富的模型压缩经验,可以帮助客户对模型进行量化、剪枝和蒸馏;
同时经过压缩过的模型,也需要推理引擎进行适配,PPIO 具备对市场上主流推理引擎的适配能力,如 TGI, vLLM, llama.cpp,openppl-llm, trt-llm 等。
为进一步提高推理的性能,PPIO 在算子融合,算子优化方面也有丰富的沉淀,可以为客户的模型做特别的适配,以满足主流推理引擎不支持某些算子或算子性能过低的情况。
最后
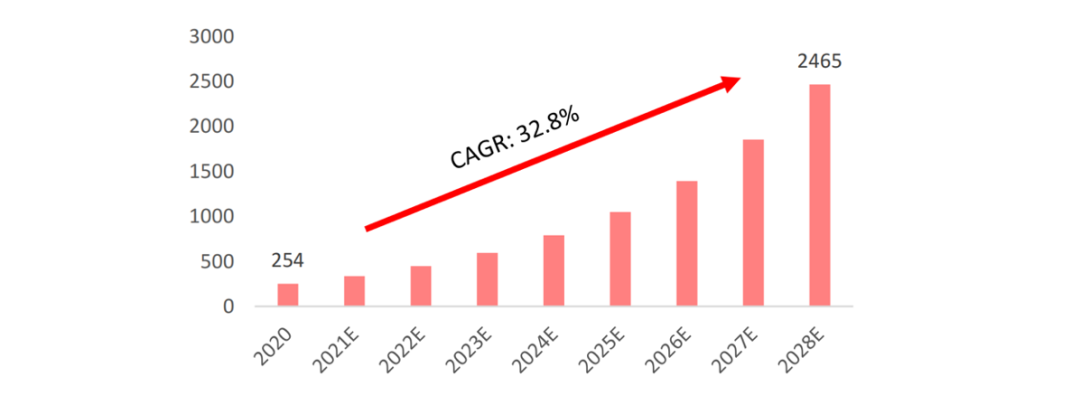
根据 Verified Market Research 的预测,2020年 GPU 全球市场规模为254亿美金,预计到2028年将达到2465亿美金,行业保持高速增长,CAGR 为32.9%,2023年 GPU 全球市场规模预计为595亿美元。
(资料来源:Verified Market Research ,中信建投)
期待,算力最终带来新的工业革命,改变全世界人类的生活方式。









 京公网安备 11010502042092号
京公网安备 11010502042092号