文 / Tom Strickx
译 / Kalinda Xie
原文链接 / https://blog.cloudflare.com/asics-at-the-edge/
在Cloudflare,我们以遍布全球100多个国家200多个城市的全球网络感到自豪。为了处理通过我们网络的所有流量,我们运用多种技术。现在让我们看一下所有这些技术的奠基石之一…ASICs。不,不是跑鞋。
ASIC代表应用专用集成电路。顾名思义,这是一种用例非常狭窄的芯片,适用于单个应用程序。这与CPU(中央处理单元),甚至GPU(图形处理单元)形成了鲜明的对比。CPU是为通用计算而设计和构建的,在很多方面做得相当好。GPU更适合图形(与其名字相符),但是在过去的15年中,已经发生了向GPGPU(通用GPU)的急剧转变,其中CUDA或OpenCL等技术使您可以使用高度并行的特性GPU进行通用计算。GPU使用的一个很好的例子是视频编码,或者最近在自动驾驶汽车等应用中使用的计算机视觉。
与CPU或GPU不同,ASIC在构建时就考虑了单个功能。Google Tensor处理单元(TPU)就是很好的例子,用于加速机器学习功能[1]或用于轨道操纵[2],其中编码了特定的轨道操纵,例如霍曼转移(Hohmann Transfer),用于移动火箭(及其有效载荷)到不同高度的新轨道。而且它们在网络行业中也有大量的应用方向。从技术角度上讲,网络行业中的用例应称为ASSP(应用专用标准产品),但是网络工程师是简单的人,因此我们更喜欢将其称为ASIC。
ASIC的主要好处是效率极其高。硬件越复杂,就越需要冷却和电源。由于ASIC仅包含其功能所需的硬件组件,因此可以减小其整体尺寸,并减小其电源要求。这对网络的整体实际尺寸有正面的影响(设备不必太笨重即可提供足够的散热),并有助于降低数据中心的功耗。
降低硬件复杂性还可以降低制造过程的故障率,因此而简化生产。
缺点是您需要在硬件中嵌入很多功能,一旦出现了新的技术或规范,任何没有采用该技术的芯片都将无法支持它(例如VXLAN)。
对于网络设备,这非常理想。总体而言,网络行业发展缓慢,需要花费大量时间才能将新技术推向市场(如IPv6,MPLS的实施,xDSL可用性等)。这意味着芯片不需要每年进行开发,而可以在更慢的周期内创造出更大的技术进步。例如,博通(Broadcom)从“战斧3(Tomahawk 3)”到“战斧4(Tomahawk 4)”花费了两年的时间,但在此过程中,它们的吞吐量增加了一倍。前面列出的好处对于网络设备也常有帮助,因为它们以较小的尺寸允许相当大的吞吐量。
与任何类型的芯片一样,构建ASIC是一个长期的过程。与CPU一样,如果硬件设计存在缺陷,则必须从头开始,并报废整个构建线。因此,开发生命周期非常长。它以FPGA(Field Programmable Gate Array现场可编程门阵列)中的原型设计开始,在该设计中,芯片设计人员可以编写他们所需的功能并确认兼容性。所有这些都是通过HDL(Hardware Description Language硬件描述语言),例如Verilog,完成的。
原型制作阶段结束后,他们开始将新的数据包处理管道烘焙到铸造厂的芯片中。此后,就不能再对芯片进行任何更改了,因为它实际上已经“烧录”到了硬件中(不同于可以重新编程的FPGA)。由于很少有硬件公司会批量购买ASIC来构建设备,这进一步增加了困难。因此,每单位的成本会急剧增加。
所有这些都意味着ASIC的迭代周期趋向于放慢脚步(例如,与Intel Process-Architecture-Optimization模型中的每年都进行的更新相比),并且通常是较小的增量更新:例如,端口速度的增加是递增的(1G→10G→25G→40G→100G→400G→800G→...),并且与芯片的SerDes(Serialiser / Deserialiser 序列化器/解串器)部分的升级捆绑在一起。
新协议的支持要困难得多,在将其加载在芯片上之前可能需要多个开发周期。
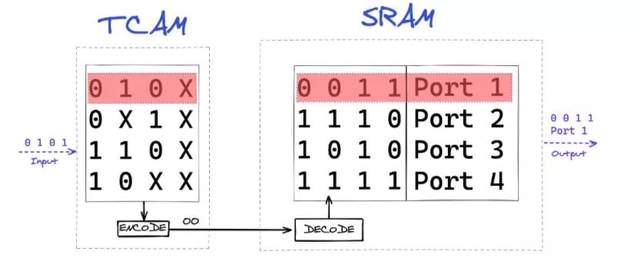
我们网络设备中的ASIC负责数据包的交换和路由,并且是第一道防线(以无状态防火墙的形式)。由于如何快速交换数据包具有绝对的本质,因此快速的内存访问是主要问题。大多数ASIC将使用一种特殊的存储器,称为TCAM(三重内容可寻址存储器)。该内存将用于存储各种查找表。这些可能是转发表(此数据包的去向),ACL表(访问控制列表,允许此数据包访问)或CoS表(服务等级表,可以为特定的数据包赋予优先级)。
CAM及其更高级的同门兄弟TCAM令人着迷,因为它们的操作与传统的随机存取存储器(RAM)有本质上的不同。虽然您必须使用存储地址来访问RAM中的数据,但是使用CAM和TCAM时,您可以直接引用您要查找的内容。它是键值存储的实体实现。
在CAM中,您使用单词的确切二进制表示形式,在网络应用程序中,该单词很可能是IP地址,因此,例如11001011.00000000.01110001.00000000(203.0.113.0)。尽管这绝对有利用的价值,但是网络需要大量IP地址,并且单独存储每个IP地址都需要大量内存。为了解决此内存要求,TCAM可以存储三种状态,而不是二进制的两种。第三种状态(有时称为“忽略”状态)允许将多个顺序数据字存储为单个条目。
在联网中,这些顺序数据字是IP地址的前缀。因此,对于前面的示例,如果我们要存储该IP地址及其后的254个IP的集合,则在TCAM中将如下所示:11001011.00000000.01110001.XXXXXXXX(203.0.113.0/24)。这种存储方法意味着我们可以问ASIC问题,例如“我应该在哪里发送目标IP地址为203.0.113.19的数据包”,ASIC可以在一个时钟周期内准备好回复,因为它不需要运行所有内存,而是可以直接引用该键。该回复通常将引用传统RAM中的内存地址,在该内存中可以存储更多数据,例如输出端口,或者是数据包的防火墙要求。
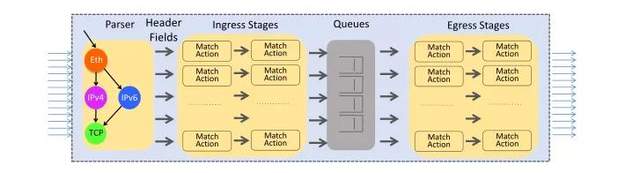
为了更深入地了解ASIC在网络设备中的作用,我们简要介绍一下一些基础知识。
网络可以分为两个主要部分:路由和交换。交换使您可以直接互连多个设备,以便它们可以通过网络相互通信。通过这种方式,您的手机可以连接电视,以播放新的家庭视频。路由是下一个升级。这种机制将所有这些交换网络互连成一个网络的网络,最后是Internet。
因此,路由器是负责引导流量通过这种复杂的网络迷宫的设备,它可以安全,尽可能快地到达目的地。在Internet上,路由器通常将使用称为BGP(边界网关协议)的路由协议来交换前缀(IP地址的集合)的可达性信息,也称为NLRI(网络层可达性信息)。
与在道路上导航一样,互联网上有多种方法可以从A点到达B点。为了确保路由器做出正确的决定,它将所有可达性信息存储在RIB(路由信息库)中。这样,即使一条路由发生任何变化,路由器仍然可以立即使用其他选项。
利用此信息,BGP守护程序可以从自己的角度为任何给定的目的地来计算出最理想的路径。该思科(Cisco)文档(链接地址)说明了守护程序计算该理想路径所经过的决策过程。
一旦有了给定目的地的理想路径,我们就应该存储此信息,因为每次我们需要去目的地采取这个信息时,计算该信息的效率非常低。该存储数据库称为FIB(转发信息库)。FIB将会是RIB的子集,因为它在任何给定时间都只会包含到达目的地的最佳路径,而RIB则会保留所有可用路径,甚至是非理想路径。
有了这些独立的组件,路由器可以眨眼间就使数据包从A点到达B点。
这是我们的ASIC需要执行的一些更具体的功能:
1. FIB安装:路由器计算出FIB后,很重要的一条是路由器必须尽快访问它。为此,ASIC会将此计算出的FIB安装(写入)到TCAM中,因此可以尽快进行任何查找。

2. 数据包转发查找:由于我们需要知道将接收到的数据包发送到何处,因此我们在TCAM中查找此信息,正如我们提到的那样,这是非常快的。
3. 无状态防火墙:当路由器在目标之间路由数据包时,您还想确保某些数据包根本不会到达目标。可以使用无状态防火墙或有状态防火墙来完成此操作。在这种情况下,“状态”是指TCP状态,因此路由器将需要了解这个连接是新建的还是已经建立的。由于维护状态是一个复杂的问题,需要存储表,并且会很快消耗大量内存,因此大多数路由器只会运行无状态防火墙。
另一面来看,状态防火墙通常具有自己的设备。在Cloudflare,我们选择将维护状态转移到我们的计算节点,因为这会严重减少状态表(所有状态一个路由器 vs所有状态组合一个X金属)。无状态防火墙再次利用TCAM来存储有关处理特定类型数据包的规则。例如,我们在边缘使用的规则之一是DENY-BOGON-RANGES,其中我们丢弃了来自RFC1918空间(和其他不可路由的空间)的流量。由于这利用了TCAM,因此都可以以线速(接口的最大速度)完成。
4. 高级功能,诸如GRE封装之类的:现代网络不再只是分组交换和分组路由,还需要更多高级功能。其中之一是封装。使用数据包封装,系统会将一个数据包放入另一个数据包中。使用此技术,可以在现有网络(覆盖图)的顶部构建网络。例如,覆盖层可用于构建虚拟骨干网,其中多个位置可通过Internet虚拟连接。
虽然您可以将数据包封装在CPU上(对于Magic Transit,我们可以这样做),但是在软件中这样做存在很大的挑战。这样,ASIC可以用已具有的内置功能来将数据包封装为多种协议(例如GRE)。您可能不希望封装的数据包在整个管道中走第二趟,因为这会增加延迟,因此这些快捷方式也可以内置在芯片中。
5. MPLS,EVPN,VXLAN,SDWAN,SDN ......等等:我已经想不到更多的领域里时髦的流行词来进行枚举了。但是虽然MPLS并不是什么新鲜的东西(第一个RFC是2001年创建的),但它是有一个相当高级的要求,就像列出的其他要求一样,这意味着并非所有ASIC供应商都会为其所有芯片来增加这些功能的应用,由于其增加了复杂性。
在Cloudflare,我们在运营全球网络的同时每天与硬件和软件供应商进行互动。今天我们在这里讨论ASIC,我们将探索硬件前景,但是同时一些硬件供应商也有自己的NOS(网络操作系统)。
现在市场上有大量的硬件可供选择,它们都有不同的功能和价格。我们科技人处在这个行业中,很难透过树木看见森林,很难清楚的来了解这里的情况。因此我们将重点关注四个重要的区别因素:吞吐量(ASIC可以推入多少位),缓冲区大小(ASIC可以在内存中存储多少位,尤其在资源争用的时期),可编程性(像Cloudflare这样的第三方程序员与ASIC直接交互有多容易),功能集(ASIC可以在路由/交换之外进行多少高级操作)。
由于不同的公司有不同的要求,因此情况如此多样。像Cloudflare这样的公司对网络硬件的期望与典型的一般公司不同。即使在我们自己的网络中,我们对构成我们网络的不同层也会有不同的要求。
博通(Broadcom)
联网室中的大象是Broadcom。Broadcom是一家半导体公司,其主要收入在有线基础设施领域(占收入的50%以上[3])。自1991年以来一直在运行,但在过去10年中,他们已成为不可阻挡的力量,部分原因是他们对苹果Apple的依赖(收入的25%来自于苹果)。作为半导体制造商,其市场主导地位主要是通过收购其他公司来实现的。一个很好的例子是对Dune Networks的收购,该公司成为StrataDNX系列ASIC系列(Arad,QumranMX,Jericho)的出色收入来源。因此,它们已成为迄今为止最大的ASIC供应商,并拥有整个以太网集成电路市场的59%[4]。
因此,他们为Cisco,Juniper,Arista和其他公司提供了大量商业芯片。直到最近,如果您想使用Broadcom SDK来加速数据包转发,您必须签署那么多NDA可能会手抽筋,这使编写它们变得更加棘手。当Broadcom开源其SDK时,这种情况最近发生了变化。让我们快速看一下他们的一些产品。
Tomahawk
Tomahawk系列ASIC是企业市场的头等大事。它们很便宜而且非常快。第一代Tomahawk芯片的线速为3.2Tbps,并具有低延迟切换。该芯片的最新一代产品(Tomahawk 4)在7nm晶体管封装中的速度为25.6Tbps [5])。由于您无法为单个软件包提供便宜,快速和完整的功能,这意味着您将失去一些功能。在这种情况下,您将缺少大多数更高级的网络技术(例如VXLAN),并且没有缓冲可言。
作为使用该芯片的其他供应商的示例,您可以看一下Juniper QFX5200交换平台。
StrataDNX(Arad,QumranMX,Jericho)
这些芯片组是通过收购Dune Networks获得的,并且是高带宽,深缓冲区芯片的集合(可用于存储和缓冲数据包的大量内存),从而可以将它们部署在包括Cloudflare edge在内的多种环境中。当边缘路由器在Jericho芯片组上运行时,我们在某些边缘位置运行Arista DCS-7280SR。从那时起,这些芯片就不断发展。自从有了Jericho2,Broadcom现在拥有10Tbps的深度缓冲芯片[6]。利用它们的结构芯片(将多个ASIC链接在一起),您可以轻松构建具有48x400G端口的交换机[7]。
思科Cisco使用QumranMX [8]构建了他们的NCS5500路由器系列。
三叉戟(Trident)
该ASIC是Tomahawk芯片组的升级版,具有复杂而广泛的功能集,同时保持了高吞吐率。最新的Trident4以极低的延迟提供了12.8Tbps的速度[9],使其成为了一个极其灵活的平台。不幸的是,它没有缓冲区空间可言,这限制了它在Cloudflare上的适用范围,因为我们需要缓冲区空间才能在我们的边缘路由器所具有的不同端口速度之间进行切换。Arista 7050X和7300X就是在此基础上构建。
英特尔(Intel)
英特尔在网络行业中以构建稳定且高性能的10G NIC(网络接口控制器)而闻名。它们不以ASIC闻名。他们通过收购Fulcrum [10] 进行了最初的尝试,后者构建了FM6000 [11] 系列ASIC,但实际上并没有真正引起人们的注意。英特尔决定在2019年通过收购Barefoot再次尝试。这个小型制造商负责Barefoot Tofino ASIC,这很可能是网络行业的根本性转变。
Barefood Tofino
Tofino [12] 使用PISA(与协议无关的交换体系结构)构建,并使用P4(与编程协议无关的分组处理器)[13] 构建,可以根据需要对数据平面(分组转发)进行编程。这是对传统网络方法的巨大突破。在传统网络方法中,很难直接对ASIC进行直接编程,而且绝对不能通过标准编程语言进行。作为一项额外的好处,P4还允许您对转发程序进行正式验证,并确保它会按预期执行操作。一个小梗需要引起注意:OpenFlow尝试过这种方法,但不幸的是,它从未真正吸引过很多人。
Tofino 1有多种变体,但高端ASIC的线速容量为6.5Tbps。由于ASIC是可编程的,所以它的功能集像您想要的那样丰富。不幸的是,该芯片没有很多缓冲存储器,因此我们还不能将它们部署为边缘设备。Arista(7170系列[15])和Cisco(Nexus 34180YC和3464C系列[16])都内置了Tofino芯片。
Mellanox
你们中有些人可能知道,Mellanox是最近被Nvidia收购的供应商,该公司还在我们的计算节点中提供了25G NIC。除了NIC,Mellanox还拥有完善的ASIC系列,主要用于交换。
Spectrum
Spectrum 3是该ASIC的最新版本,具有12.8Tbps的交换能力,具有广泛的功能集,包括深度数据包检测和NAT。该芯片可以构建密度高达25.6Tbps的高速端口设备[17]。在缓冲方面,没有什么可说的(64MB)。Mellanox还构建自己的硬件平台。与下面的其他供应商不同,它们没有与Mellanox操作系统一起提供,而是为您提供了多种运行在顶部的选择,包括Cumulus Linux(Nvidia还收购了它)。
如前所述,尽管我们广泛使用其NIC技术,但目前我们的网络中没有任何Mellanox ASIC芯片。
Juniper
Juniper是网络硬件供应商,目前是Cloudflare的最大网络设备供应商。就像在Broadcom一节中先前提到的那样,Juniper向Broadcom购买了一些硅片,但是他们还有大量的自产硅片,可以分为两个家族:Trio和Express。
Express
Express系列是交换型系列,其带宽是优先考虑的问题,同时它仍保持广泛的功能。这些芯片与Broadcom StrataDNX芯片的应用环境相同。
Paradise(Q5)
Q5是新一代的Juniper网络交换ASIC [18]。虽然它本身不具有较高的线性(500Gbps),但是当将其与带有结构芯片的机箱(在这种情况下为Clos网络)组合在一起时,它们可以生产吞吐量高达12Tbps的交换机(或线卡)[19] 。除了支持高吞吐量,密集的网络设备外,该芯片还配备了由外部HMC(混合内存立方体)提供的惊人的缓冲区空间(每个ASIC 4GB)。在此HMC中,他们还决定放置FIB,MAC和其他表(因此没有TCAM)。
Q5芯片用于其QFX1000交换机系列中,其中包括QFX10002-36Q,QFX10002-60C,QFX10002-72Q和QFX10008,它们都作为边缘路由器或核心汇聚交换机部署在我们的数据中心中。
ExpressPlus(ZX)
ExpressPlus是Paradise芯片系列中功能更丰富,更新更快的版本。它为每个芯片提供了两倍的带宽(1Tbps),并以2U尺寸(PTX10002)内置在组合Clos结构中,达到6Tbps。它还具有更大的逻辑规模,其中包含更大的缓冲区,更大的FIB存储空间和更多的ACL空间。
ExpressPlus与最新的兄弟Triton一起启发了一些IP路由器的PTX系列。
Triton(BT)
Triton是Express系列中最新一代的ASIC,每个芯片的容量为3.6Tbps,为某些真正的带宽密集型硬件铺平了道路。Triton和ExpressPlus均具有400GE功能。
Trio
Trio系列芯片主要用于功能强大的MX路由平台,目前已是第5代。

Juniper MPC4E-3D-32XGE线卡
Trio Eagle (Trio 4.0) (EA)
Trio Eagle是Trio Penta的上一代产品,可以在MPC7E线卡上找到。它是一个功能丰富的ASIC,具有400Gbps的转发能力,显着的缓冲区和TCAM容量(这是路由平台ASIC所期望的)。
Trio Penta (Trio 5.0) (ZT)
Penta是新一代路由芯片,专为MX平台路由器而设计。除了是一个非常强大的芯片(每个ASIC能够提供500Gbps的能力)之外,Juniper还可以构建容量高达4Tbps的线卡,该芯片还具有很多强大的功能,可提供高级硬件卸载功能,例如MACSec或Layer 3 IPsec。
Penta芯片包装在MPC10E和MPC11E线卡上,可以安装在MX机箱路由器的多种变体中(包括MX480)。
思科公司(Cisco)
最后但也非常重要的是思科Cisco。俗话说“没有人会因为购买思科而被解雇”,他们是周围市场里最大的网络解决方案供应商。就像Juniper网络一样,他们拥有商户硅和自家生产的混合产品。尽管我们以前曾将Cisco路由器用作边缘路由器(Cisco ASR 9000),但现在情况已不再如此。我们仍会充分利用它们的Nexus 5000系列和Nexus 9000系列交换机来满足ToR(机架式)交换需求。
Bigsur
Bigsur是为Nexus 6000交换机系列开发的定制芯片(令人困惑的是,交换机本身称为Cisco Nexus 5672UP和Cisco Nexus 6001)。在我们的特定型号Cisco Nexus 5672UP中,其中7个互连,可提供10G和40G连接。不幸的是,Cisco对其ASIC功能持更为严格的态度,因此我无法像使用Juniper芯片那样深入。从功能上讲,我们的边缘网络中对它们的要求不高。它们是简单的第2层转发交换机,没有附加要求。像Juniper Express芯片一样,在缓冲方面,他们使用称为虚拟输出队列的系统。与Juniper芯片不同,Bigsur ASIC并没有很多TCAM或缓冲区空间。
Tahoe
Tahoe是在Cisco 9300-EX交换机(也称为LSE(叶脊椎引擎))中存在的Cisco ASIC。与Bigsur(1.6Tbps)[20] 相比,它提供了更高密度的端口配置。总体而言,此ASIC是Bigsur芯片的成熟版本,具有更多高级功能,例如高级VXLAN + EVPN结构,更大的端口灵活性(10G,25G,40G和100G)以及增加的缓冲区大小(40MB)。我们在边缘数据中心和核心数据中心中广泛使用此ASIC。
在决定购买下一代Cloudflare网络设备时,会有许多不同的因素参与到决策中。这篇文章只是从技术层面肤浅的来探讨,没有涉及到其他很多因素,如生态系统贡献,开放性,互操作性或定价等等。我们所写的这么长的文章是多谢了其他各位网络工程师的贡献 --- 可以说这篇文章是写在巨人的肩膀上的。尤其要感谢UCSC的Jim Warner的出色工作,David Roy撰写的有关新MX平台的精彩书籍(Day One:Inside MX 5G)以及Juniper QFX阵容中的最佳书籍:道格拉斯·理查德·汉克斯(Douglas Richard Hanks Jr.)的Juniper QFX10000系列,和最后Justin Pietsch的 Summary of Network ASICs。

@2017-2024 LiveVideoStack版权所有. 京ICP备20010033号-1  京公网安备 11010502042092号
京公网安备 11010502042092号







