AI模型近年来被广泛应用于图像、视频处理,并在超分、降噪、插帧等应用中展现了良好的效果。但由于图像AI模型的计算量大,即便部署在GPU上,有时仍达不到理想的运行速度。为此,NVIDIA推出了TensorRT,成倍提高了AI模型的推理效率。本次LiveVideoStack线上分享邀请到了英伟达DevTech团队技术负责人季光一起探讨把模型运行到TensorRT的简易方法,帮助GPU编程的初学者加速自己的AI模型。
文 / 季光
整理 / LiveVideoStack
01 关于NVIDIA GPU
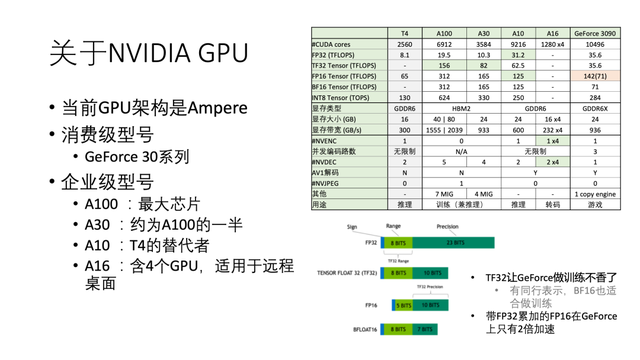
首先介绍英伟达的GPU。上一代GPU架构是图灵Turing,当前架构是安培Ampere。Ampere消费级型号都是30开头,包括3090、3080、3070等;企业级型号用于数据中心,包括A100、A30、A10、A16等。由于企业级型号很多,所以简单介绍一下这些型号的用途。
A100是芯片面积最大的GPU,适合做训练;而A30的能力大约是A100的一半。但这两个GPU的特点是它们都支持新的数据格式TF32,并且在Tensor Core上做矩阵乘法有很高的吞吐(见上图表格中标绿处)。TF32在训练时非常有用,可以部分替代FP32。另外A100/A30支持MIG,可在单一操作系统中动态切割成多GPU,也可兼用于推理。
A10是T4的替代者,它的特点是FP32/FP16吞吐很高,比较适合做推理。
A16比较独特,这个卡上含有4个GPU,每个GPU上带着1个NVENC和2个NVDEC引擎,它更适合做转码。
GeForce 3090是消费型号,它的GPU型号与企业级的有所不同,计算能力有所欠缺,例如它的FP16的矩阵乘算力是142 TFLOPS(FP16累加,精度有限)或71 TFLOPS(FP32累加)。相比之下,A10的FP32累加矩阵乘可达125 TFLOPS,比它高出很多 。因此无论是做训练还是做推理,GeForce 3090在很多情况下都比不过企业型号。
02 GPU编程基础

GPU算力的发挥要靠GPU上的程序运行出来,因此需要我们编写GPU的程序。GPU编程又被称作异构编程,与CPU编程有不一样的地方。
对于CPU程序,程序和数据都放在主存(即内存)上,这是我们熟悉的方式。而上图左边则是GPU程序的运行方式。GPU有自己的存储器,即显存。要把程序运行在GPU上时,我们需要先把数据从主存拷到显存上,然后启动GPU程序进行计算;当计算完成时,需要把数据从显存拷回主存。以上就是异构编程的思想。简单来说就是将数据拷至异构的处理器上,启动程序,最后将数据拷回。
上图右边是个比较完整的程序,演示了上述思想。程序用cudaMalloc分配出显存上的变量a和b(由显存指针dp_a和dp_b指向),用cudaMemcpy把a从主存拷贝到显存上,然后启动GPU程序。黄色高亮的这段GPU程序称作CUDA kernel,它所使用的数据都来自显存。计算完成后,cudaMemcpy把结果b拷回主存,最后cudaFree释放起初分配的显存。
掌握“数据拷到显存-启动GPU程序-数据拷回主存”这一思想是非常重要的。对于熟悉C++编程的人来说,调用相关函数比较简单,但要写出CUDA kernel还需要额外花功夫。我们特别希望在使用GPU时可以减轻编程负担,通过API调用方式就让程序在GPU上运行起来。这也是TensorRT这种GPU加速库出现的原因。
03 GPU转码流水线中的TensorRT
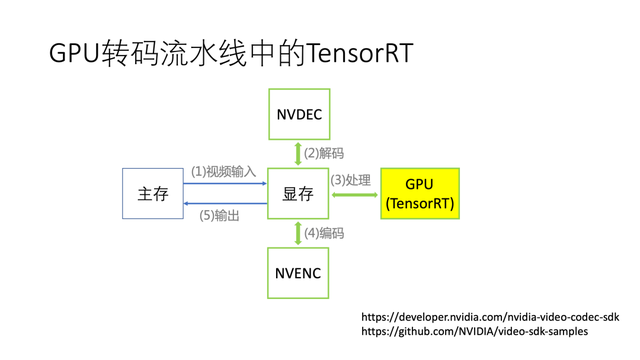
前面示例代码中的数据是单个浮点数,这是一种简单场景。而更复杂的场景下,拷贝的数据可以是单张图片或连续图片。无论如何,在主存和显存间拷贝数据是有代价的,在数据量大时会成为程序运行的瓶颈,我们需要尽可能地减少或者避免。
以视频转码为例,如果输入数据是编码过的视频码流,可以利用GPU上的硬件解码器解码,把解出的图片存放在显存,再交给GPU程序处理。此外,GPU上还带有硬件编码器,可以将处理后的图片进行编码,输出视频码流。在上述流程中,无论是解码,还是数据的处理,还是最后的编码,都可以使数据留在显存上,这样可以实现较高的运行效率。
04 用TensorRT加速AI模型推理

深度学习应用的开发分为两个阶段,训练和推理。TensorRT用来加速推理。
TensorRT的加速原理大体在这几个方面:
TensorRT可以自动选取最优kernel。同样是矩阵乘法,在不同GPU架构上以及不同矩阵大小,最优的GPU kernel的实现方式不同,TensorRT可以把它优选出来。
TensorRT可以做计算图优化,通过kernel融合,减少数据拷贝等手段,生成网络的优化计算图。
TensorRT支持fp16/int18,对数据进行精度转换,充分利用硬件的低精度、高通量计算能力。
05 TensorRT的加速效果

我们通过一些例子来说明TensorRT的加速效果。
对于常见的ResNet50来说,运行于T4,fp32精度有1.4倍加速;fp16精度有6.4倍加速。可见fp16很有用,启用fp16相较于fp32有了进一步的4.5倍加速。
对于比较知名的视频超分网络EDVR,运行于T4,fp32精度有1.1倍加速,这不是很明显;但fp16精度有2.7倍加速,启用fp16相较于fp32有了进一步的2.4倍加速。
可以看出不同模型的加速效果不同,一般来说卷积模型加速较为显著,而含大量数据拷贝的模型加速效果一般,且fp16无明显帮助。
06 快速上手TensorRT

TensorRT该怎么用呢?本质上就是把训练框架上训练好的模型迁移到TensorRT上。以下是三种方案:
1)通过框架内部集成TensorRT
TensorFlow集成了TF-TRT,PyTorch还有TRTorch,调用这些API就可以把模型(部分地)运行在TensorRT上。它们的使用方式都比较简单,通过框架中的API就能运行,但是很多情况下没有达到最佳效率。
2)比较硬核的方法是使用TensorRT C++/Python API自行构造网络,用TensorRT的API将框架中的计算图重新搭一遍。这种做法兼容性最强,效率最高,但难度也最高。对于这种方法,我们之前在GTC China做过两次报告(TENSORRT: 加速深度学习推理部署,利用 TENSORRT 自由搭建高性能推理模型
https://on-demand-gtc.gputechconf.com/gtcnew/sessionview.php?sessionName=ch8306-tensorrt%3a+ 加速深度学习推理部署),有兴趣的话可以看一看,其难点是需要了解TensorRT的layer都有哪些,以及从原始框架的OP(即操作)跟这些layer的对应关系。
3)今天推荐的方法是从现有框架导出模型(ONNX)再导入TensorRT。
它的优点是难度适中,效率尚可,可以算作捷径。需要解决的问题是:如何从训练框架导出ONNX,以及如何把ONNX导入TensorRT。
07 解决如何导出与如何导入
第0步:了解TensorRT编程的基本框架

上图展示的代码是TensorRT最基本的使用方法。
1.作为准备工作,先造了logger,又造了builder,从builder造出network,这些对所有TensorRT程序都是固定的。
2.接下来高亮的这一部分是通过TensorRT的API把计算图重建起来,使TensorRT上的计算与训练框架原始模型一模一样。这段代码可以非常长,比如上百行。
3.做完之后利用network可以构建TensorRT engine(build_cuda_engine),构建时间根据网络大小有长有短,短的几秒,长的可达几分钟甚至几小时。
4.构建好engine后可以调用运行。而且engine可以保存到磁盘,在第二次运行的时候,不需要再次build,直接load就可以运行。
上图中的d_input、d_output是前面提到的异构编程中的显存地址。
高亮的这一部分可以非常复杂,但为了省事,我们使用ONNX Parser自动搭建网络,让这一部分自动完成。
所以基本流程是这样:先从训练框架导出ONNX,再用TensorRT自带的工具trtexec把ONNX导入TensorRT构建成engine,最后编写一个简单的小程序加载并运行engine即可。
第1步:从框架中导出ONNX

ONNX是中立计算图表示,PyTorch有TouchScript,TensorFlow有frozen graph,都是框架特有的对于计算图持久化的办法。ONNX是平台中立的,理论上所有框架都可以支持的表示方法。
一般情况下导出的ONNX仍具备运行能力,但有时不能直接运行,而是需要补充ONNX Runtime。比如导出的ONNX中具有特殊的算符,例如Deformable Convolution,它不是ONNX标准OP,但通过扩展ONNX Runtime可以让导出的ONNX跑起来。
但ONNX能不能运行并不是可被TensorRT顺利导入的先决条件。也就是说,导出的ONNX不能跑也没关系,我们仍有办法让TensorRT导入。这一点会在下文举例说明。
上图可以看到PyTorch导出ONNX的示例代码。其中的resnet50是一个PyTorch nn.Module对象;verbose设为True可让ONNX用文本方式打出来,对调试很有用;opset可以设置最高到12,版本越高,支持OP数量越多。
第2步:用Parser将ONNX导入TensorRT

TensorRT官方开发包自带可执行文件trtexec。它可以接受ONNX输入,根据ONNX将TensorRT网络搭建起来,构建engine,并保存成文件。这一系列动作通过图中的命令就可以做到。
其实trtexec也可以自己编程来实现,不过一般来说没有必要。
trtexec运行成功说明TensorRT用自有的层重建了等价于ONNX的计算图,而且计算图被顺利构建成了engine。保存成文件的engine将来可以反复使用。
第3步:运行Engine

最后一个步骤比较简单,就是加载engine文件,提供输入数据,即可运行。C++和Python的示例代码可以从这里找到。(
https://github.com/NVIDIA/trt-samples-for-hackathon-cn)
注意一定要对比TensorRT与原框架的计算结果,算出两者的相对误差均值。理想情况下fp32的误差在1e-6数量级,fp16的误差在1e-3数量级。
另外,我们都很关心模型跑到TensorRT上有多少加速比。熟悉CUDA编程的朋友可以用CUDA event测量运行时间,但要注意stream要设置正确。另外还有一种较粗略的简易方法:做一次GPU同步,然后取时间t0;启动GPU程序;再做一次GPU同步,取t1,得t1-t0,这就是GPU程序的运行时间。
(示例代码见这里:https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/python/app_onnx_resnet50.py )
这里关键需要理解GPU同步的含义:GPU程序是从CPU启动的,即在CPU端调用TensorRT的execute函数,其实是把GPU程序放进任务队列,放好了就返回了,并不等GPU程序执行完毕;而GPU程序的执行却是异步的。在CPU上做一次GPU同步,就是让CPU等待此前提交的GPU任务全部执行完。基于以上,我们就可以理解为什么取时间之前要做一次GPU同步。
这里有个问题:这个简易方法在什么时候不准确?简单的说,这个方法会有误差,如果要统计的GPU程序运行时间较短,就很难得出准确结果。这种时候,用CUDA event才是终极解决方法。
08 导出ONNX:疑难问题

前面说得都是最顺利的情况。我们看看对于导出ONNX,不顺利的情况有哪些:
如果遇到ONNX不支持的操作,解决办法是升级框架和ONNX导出工具,使用当前支持的最高opset。
但这样可能还不够,因为有些PyTorch官方的OP在ONNX中仍然没有定义(或无法组合得到)。所以在导出时加上选项ONNX_FALLTHROUGH,即便没有定义也可以导出。
如果遇到开发者自定义的OP,则需要确认为自定义的Function子类增加symbolic函数,从而为自定义OP取ONNX节点名。
(例子见这里:https://github.com/shining365/EDVR-TRT/blob/master/basicsr/models/ops/dcn/deform_conv.py#L114 )

此外,用trtexec把ONNX导入TensorRT时可能会遇到报错。一种常见的情况是不支持的OP,这个稍后再说。另一种情况是TensorRT Parser对ONNX网络结构有特殊要求。具体地,我们看一个例子。
上图中高亮的报错信息是”Resize scales must be an initializer!”为了得到更丰富的信息方便调试,请运行trtexec时打开--verbose选项。从图中可以看到,这个Resize节点有385,402,401这3个输入。这3个数字并不是输入的具体值,而是输入变量的名字。我们需要进一步看看这3个变量都是怎么生成的。

请在导出ONNX时确保设置verbose=True,可得到文本描述的ONNX,见上图。可以看到Resize节点在图中最下方,它的3个输入变量已被高亮出来,它们有各自的计算过程。由于ONNX本身是个计算图,我们可以画一张图将这一部分更清楚地展现出来。
09 ONNX手术刀:Graph Surgeon
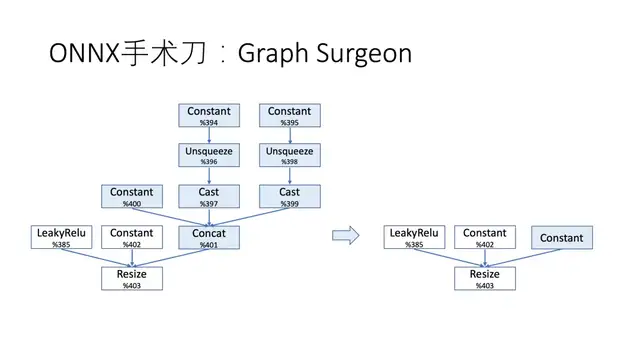
上图是有关这个Resize的ONNX子图。它的第三个参数变量401来自Concat操作,将3个变量Concat在一起:其中一个是Constant,另外两个是Constant经过了Unsqueeze与Cast,做了数据类型的转换。
前文报错信息“Resize scales must be an initializer!”指的是Resize的第三个参数不能是变量,而必须是Constant,所以我们需要把蓝色的这部分子图转换成一个Constant,变成右边的样子。一旦做到,TensorRT Parser就会正常运行下去。
这个转换在理论上可以做到,原因是这部分子图的叶子节点都是Constant,具体值都写在里面,我们按计算图手工做一下相关计算,得到结果后存放在新建的Constant节点里就可以了。实现它的工具是Graph Surgeon。

Graph Surgeon像手术刀一样可以修改ONNX计算图。上图就是用Graph Surgeon完成计算图转换的代码。
1.首先找到符合条件的Resize节点,其筛选条件就是它的第三个输入变量应来自Concat节点。
2.然后我们对这个Concat的所有输入参数建立一个while循环,一直往上走,直到找到Constant,并把Constant里面的值放进values中。这样走完for循环后,所有要合并的值都已经存进values中。
3.最后新建Constant节点,用numpy的concatenate函数将值合并填入该节点,并为该节点连接好输出。
Graph Surgeon的一个完整示例代码见这里(
https://github.com/NVIDIA/trt-samples-for-hackathon-cn/blob/master/python/app_onnx_custom.py )。随着大家做Graph Surgeon的经验积累,特殊情况处理的经验会越来越丰富,你将会积累更多的节点处理方式,从而让更多模型被TensorRT Parser正确解析。
10 遇到不支持的操作

当trtexec报告不支持的OP时,我们不得不编写TensorRT Plugin。TensorRT Plugin是TensorRT功能的扩展,需要什么我们就可以写什么,也可以说是“万金油”。
编写TensorRT Plugin的思想是套用模板在里面“填空”。最关键的那个“空”就是GPU上的计算程序。对于缺少CUDA编程经验的用户,可以尽量复用原来代码,避免新写CUDA kernel。
这里我们演示了如何把EDVR里面的Deformable Convolution包装成TensorRT plugin(代码在这里:
https://github.com/shining365/EDVR-TRT/blob/master/trt_onnx/DeformConvPlugin.h )。对于这个PyTorch的例子来说,我们尽量保持原始代码不变,原封不动地把相关代码片段提取出来,并拷贝了原始代码的编译选项,使得CUDA代码可顺利编译。
11 使用fp16/int8加速计算

如果模型已经成功地跑在了TensorRT上,可以考虑使用fp16/int8做进一步加速计算。TensorRT默认运行精度是fp32;TensorRT在Volta、Turing以及Ampere GPU上支持fp16/int8的加速计算。
使用fp16非常简单,在构造engine时设置标志即可。这一点体现在trtexec上就是它有--fp16选项,加上它就设置了这个标志。
我们举例说明fp16加速计算的重要意义。对于EDVR,用ONNX导出的模型,直接运行fp32加速比是0.9,比原始模型慢,但是打开fp16就有了1.8倍加速。fp16对精度的影响不是很大。
int8量化需要校正数据集,而且这种训练后量化一般会损失精度。如果对此介意,可以考虑使用Quantization Aware Training,做训练时量化。
12 发挥TensorRT的极致性能

前面讲的是TensorRT的一般用法,当你成为TensorRT熟手之后需要考虑如何发挥TensorRT极致性能。
1)API搭建网络
对于EDVR来说,我在TensorRT上用过两种方式运行,一种是用ONNX导出,它的fp32和fp16精度下的加速比是0.9和1.8;另一种是API搭建,它的加速比是1.1和2.7。可以看出API搭建有一定收益。假如模型特别重要,就要考虑用API搭建。
2)优化热点
通过Nsight Systems可以找到时间占用最多的操作,对它进行重点优化。
3)用Plugin手工融合所有可以融合的层
以上这些方面都做到的话,基本上就可以做到在TensorRT上的极致性能。
13 总结与建议

今天我们推荐的开发方法是用ONNX Parser导入模型。这里需要熟悉Graph Surgeon用法,针对各种特殊情况处理。有可能需要自定义Plugin,包装现有CUDA代码。我们推荐使用混合精度,特别是fp16用法简单、效果不错;int8有更好计算性能,但一般会有精度下降。如果想要进阶,要试着使用API搭建网络,并且编写与优化CUDA kernel。
14 示例代码

以上就是我分享的全部内容,谢谢。
直播回放:
https://www.livevideostack.cn/video/gary-ji/
- The cover from creativeboom.com

@2017-2024 LiveVideoStack版权所有. 京ICP备20010033号-1  京公网安备 11010502042092号
京公网安备 11010502042092号








