编者按:LiveVideoStack很荣幸地邀请到了来自Rokid应用平台算法负责人,王文兵老师,为我们分享介绍AR下的RTC技术与应用。
文/王文兵
整理/LiveVideoStack
我是王文兵,Rokid应用平台的算法负责人,曾就职于百度、MTK,现在在Rokid负责AR以及语音识别系统、视觉识别系统的框架设计和算法研发,今天为大家带来的topic是AR下的RTC技术与应用。
原创2023-02-08 11:38·LiveVideoStack
很高兴今天能够和大家分享关于AR以及在AR下RTC相关的一些东西。今天主要站在以下4个方面分享:首先是AR与RTC的应用场景,即包括AR本身的应用场景以及这些场景里面跟RTC有关的;第二块就是在AR下RTC的着力点在哪;第三块是RTC在AR中的技术应用;第四块说说自己理解的RTC在AR里的挑战和想法。
01 AR与RTC的应用场景
我们先给大家简单的介绍一下在AR里我们的应用场景有哪些。为什么会提这些点呢?我们在2020年向国内的客户推AR眼镜的时候,客户是基本上是不太能理解的。因为那时大家都不懂这个东西对企业能带来什么价值?但是在国外,像德国本身就是工业起家的,尤其它们自己也在推工业互联网4.0,它们就能够反过来找我们谈,找我们要AR眼镜,这就是在早期时候的一些差距。到2021年的时候,国内的客户会主动跟我们聊AR眼镜对他们的帮助有哪些,因为大家可能感受到了趋势,也更愿意去尝试去了解AR眼镜的用途。

我就以这一张图简单的给大家说一下AR上的应用。Rokid是一家专注新一代人机交互技术的产品平台公司,有自己的OS和云,基于这点我们会有自己的AR硬件,我们自己会对外输出这些产品,已经在淘宝、京东上可以看到的ToC的Rokid Air眼镜;有面向数字文化(博物馆、景区等)的Rokid Air Pro,也有ToB的Rokid Glass和面向重工业的X-Craft。同样,我们也与一些硬件厂商合作,它们会集成我们的系统,然后整个输出一个硬件的产品。同时,我们也对外推出Rokid Solution,包括针对各行各业输出一些解决方案。当然,也有其它的客户基于我们的硬件跟软件做第三方。
我们整个的应用场景大概有三块:一块是数字文化相关,展示文物以及教育知识等应有的生动形象,让文物和文化遗产“活”起来;第二块是工业,包括制造、汽车等,还有电力等,用AR赋能一线人员提升协作效率,打造“超级工人”;还有一块是B端和G端上的公共服务等。那么,我们AR在行业应用的一些点,哪些是跟我们RTC相关的呢?我就以公司销售端对外播放的一个视频向大家展示。
视频提到了几个点:
第一个是高清的音视频。因为在AR尤其是在B端的应用上很多,比如我们的客户是在山区、海上或者是其它的煤矿这种弱网环境,我们怎么样能够做到高清音视频这是其中一个点;
另外一个点是面向B端的时候, 主要就是低碳出行和高效工作;所谓的低碳出行,以前出现什么现场问题专家会立刻赶过去,现在就是减少飞机/火车等交通工具带来的排放,线上解决问题;至于高效工作,我们会有远程协作平台,平台会允许专家端跟现场客户以第一视角来连线,并且它会根据你这边的现状去做一些指导,这个指导涉及AR的一些标注。最右图中红色的跟绿色的是2D或3D的数字模型,是虚拟的数字内容,它会告诉你这一块需要怎么做或者一些东西扔过来会显示在上面。这些数字的模型会根据SLAM的技术,锚定在技师现场,它是不会变的。专家端看到的东西都是现实世界的内容叠加上数字世界的内容,虚拟加上现实是融合在一起的,专家端可以始终以这个视角看到。
这里面还包括协作、共享。比如说它遇到什么问题随时需要跟你说明这个问题怎么解开,从电脑端找任何的图片、截图、文字都会跟你协作发送过来。
这些都是AR下RTC的应用。
AR下RTC遇到通讯的问题:
第一个就是弱网的环境。刚才有提到,包括有一些电力的人是带着头盔爬杆上去,他的双手是一直在操作的,而AR头环是一直戴在眼睛上的。不管是山区、弱网还是海上油田等,弱网是最基本改变不了的;
第二个是嘈杂的环境,就是经常通信起来专家端听不清,因为工厂的噪声特别大。像核电现场的噪声我们这边需要做处理,各种化工区现场制造车间的嘈杂声音,这些声音都是影响我们RTC通信的;
视听的视野是什么意思呢?就是在AR音频中Audio跟Video是典型不一样的,Audio Focus有全局感受野,所以在360°的环境中,声音是能够全局捕获到的,但是因为Video是纯球体360度,没法浏览出Video的Focus,是需要依赖Audio的声音来进行感受野的切换。Audio可能此时出声打游戏的时候有声音来了,我可能会转过来。所以这是它们一个大的不同点,这也是我们会在AR的RTC上会讲到,对Audio做一些处理的原因;
还有个是开放式的喇叭,就是在AR上我们喇叭的出声口和speaker是在耳朵上,大概离耳道口有3厘米的距离。其实这个距离下,比如说本来弱网就使得声音很糟糕,再离开一点距离基本上就没法听到更有效的声音,所以这是我们现在在AR上做RTC试图去解决的一些问题。
02 AR RTC中的着力点
RTC的着力点,是否不同的行业都需要卷RTC?其实做RTC的,不管是大厂,包括腾讯、头条等,其实大家都做RTC。从我们自己的角度出发,我们要做的不仅仅是RTC本身,那我们要做的点在哪?

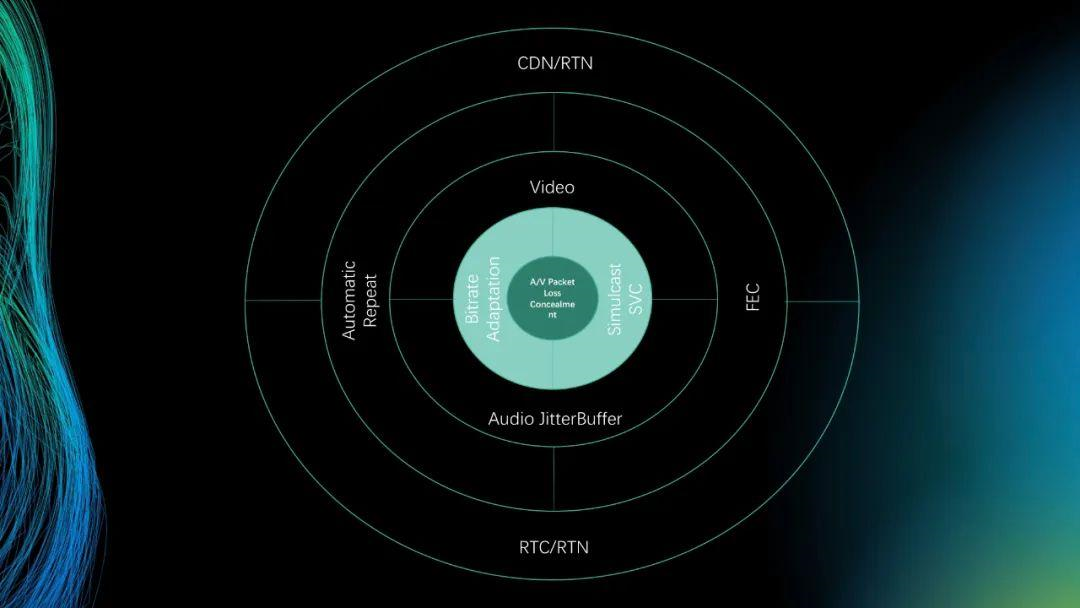
为什么我们不去讲RTC本身,包括我们自己用一些合作伙伴的SDK,他们的SDK已经可以做到从A端到B端不管是抖动、时延还是抖动本身时延的方法提升已经很大。我们不试图在这个基础上卷网络的优化,卷一些云端的分发、链路。
我们做的事就是里面核心的两块标颜色的。我们从最外层讲RTC有RTC的量度或者CDN的量度。一整套已经有成熟的产品,靠近里面的不管是网络传输上的重传、FEC这些也不需要我们做,再到里面的网络抖动,其优化也有很多,像腾讯的SDK针对它专门做算法上的优化。其实我们自己focus的点在于音视频的数据最终到了工业头盔等产品上还能怎样进行音质、画质上的提升,这就是我们在做的一些事,包括最里面的源泉是语音跟视频发生了切切实实的数据丢失,更长远一点就是在解码上我们是否能够做出一些改变,用我们的自己场景做优化,这就是我们自己在做的,讲RTC实际上是在收到数据之后。
03 AR RTC中的技术应用
下面,我从以下四个方面给大家介绍一下AR里面我们做的RTC的技术应用点。
第一块是语音的降噪,就是我们刚才提到的工厂嘈杂噪声;第二块是超分,就是为了把弱网下工人或者技师端看到的一些小画面进行超分;第三块涉及音频的补偿,对于一些确切发生丢包的数据,我们会把它的语音数据进行算法处理,使得它听起来会更顺滑;第四块是空间声场,其实我们解决的就是刚刚提到的在AR或者是VR里现在已经是很现实的问题,打游戏的时候全依赖声音来切画面进行一些实时的渲染变更,包括编解码上的处理。

语音的降噪涉及到的模块偏技术。整个语音降噪就是在于把一个带噪的语音x(n)经过一些滤波处理来得到预测的y(n),这个y(n) 其实就是预测出的干净语音,通过和参考的d(n)比较,看差值是否能满足迭代收敛的条件。从传统的LMS,再到AP,发展到如今大家都是在用深度学习的方向去做这件事,因为它可以针对不同工厂、不同场景下的噪声做专门的处理和滤波。我们也是采用深度学习上的一些线路。

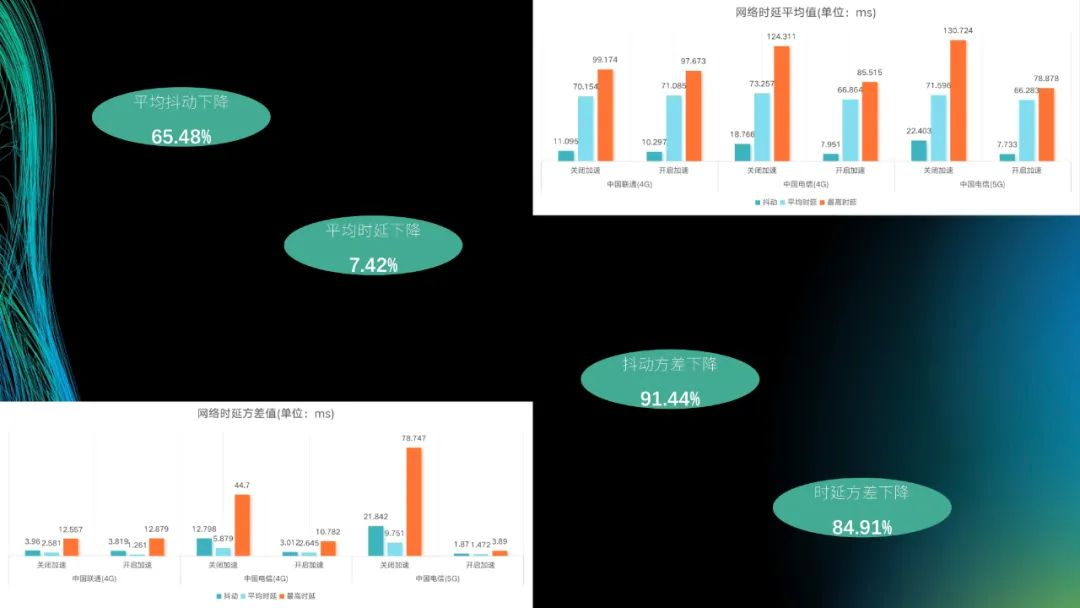
我们也是基于CRN加上复数卷积的方式进行处理,包括对网络本身去做一些端上跑,达到工厂噪声、核电噪声等,到最终消噪的目的来提升通信体验。我们自己在AR眼镜终端上同时配合定向波束,加上降噪跟语音识别技术,最终提升至95db的工业噪声下到90+%的语音识别准确率。当然降噪本身是为了提升RTC,专家端听到的也可以更好。这里面的测试结果就是2021年的DNS测试数据,外加核电工业噪声后得到的PESQ的提升结果。就是降噪前后以及STOI的数据。

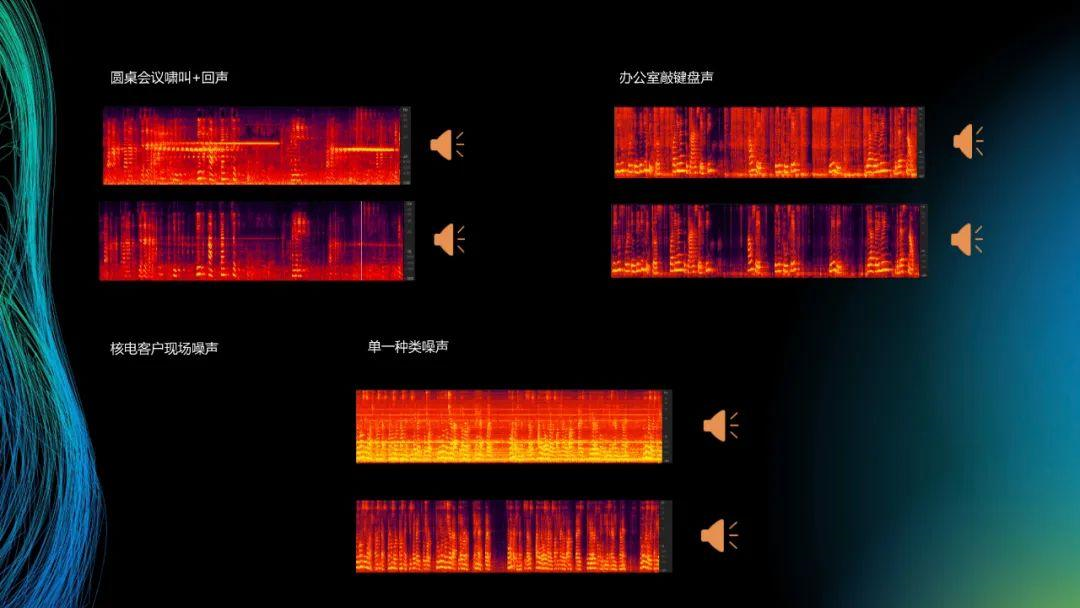
圆桌会议是真实的应用场景。我们用客户的SDK,但是客户的SDK在一些场景下啸叫跟回声解决不掉,那些垂直黄线其实就是噪声,然后我们把自己的降噪用进去,就可以一定程度上消除掉啸叫。另外一个就是核电客户现场的噪声,本身声音是有点吵的,整个平台都是客户现场机器噪声,听不到语音内容的;最后就是很普通的办公室的这里面的声音。
其实深度学习解决了传统解决不了的一个问题,就是传统的信号处理只能解决一些平稳的噪声,对于非平稳的“pia pia pia”或者是工厂巨大的机器噪声收敛不了或者不停的收敛效果就会不好。
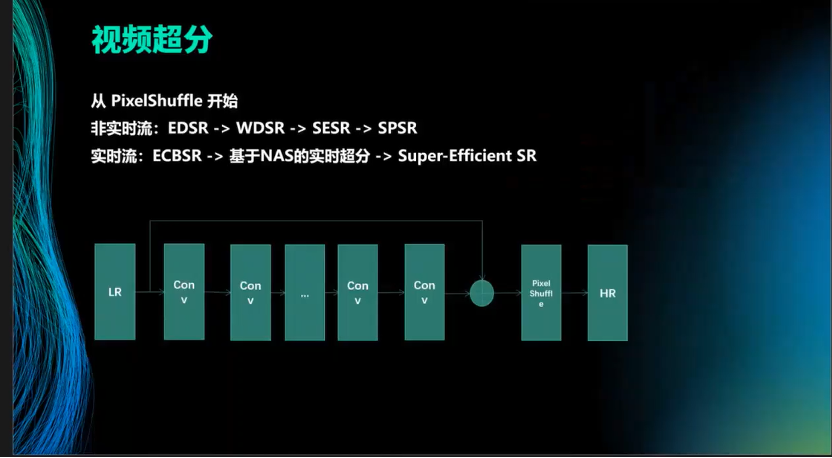
超分是针对AR头环端收到的一些数据,数据本身视频分辨率只有360P,在山区等弱网下收到RTC的数据后,我们会再做实时的超分。超分本身这件事就是从深度学习PixelShuffle后的时候开始,基本上网络结构就是呈现到一个从低分辨率的LR再到HR的过程。Shuffle本身是视频超分的一个恢复操作,非时流的经历过一些发展路线,大家都是换中间的一些骨架,包括ResBlock、SEBlock等,再到提出实时流的框架ECBSR,大家会基于NAS做实时检索,自己做搜索找一个更达到目标的东西,别人再从参数化去做。我们自己也是基于这个大的框架,只不过本身卷积Block就会根据端上的性能做一些裁剪使得它在端上能够做到实时。
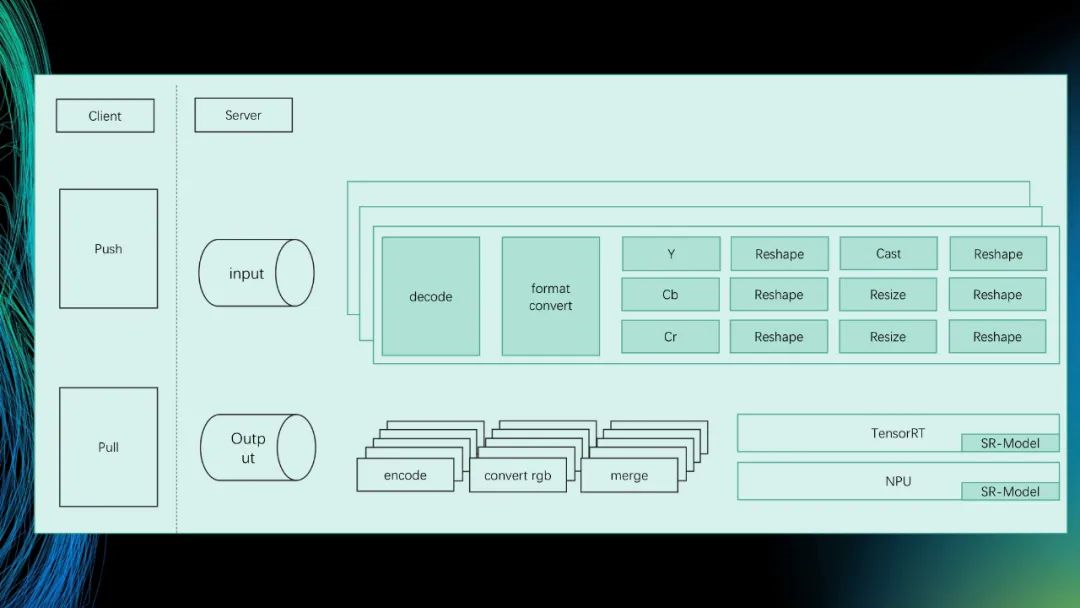
除了框架之外,我们会同时把CPU跟GPU放一起,因为我们的设备上有NPU加速,把这几个流水线跑起来。其实一次性把很多东西放在GPU上去做,然后有一些东西在服务端可以直接走TensorRT的处理,在我们端上的话就直接走NPU的。我们会根据算法和硬件的性能去设计、调优这个pipeline,我们把很多能在NPU上操作的全部移到4核NPU上,包括利用图片的解码,以及解码的数据直接放在CPU上放着。NPU直接去获取,减少CPU跟区间的通信,同时把CPU的资源利用起来做一些并行处理。
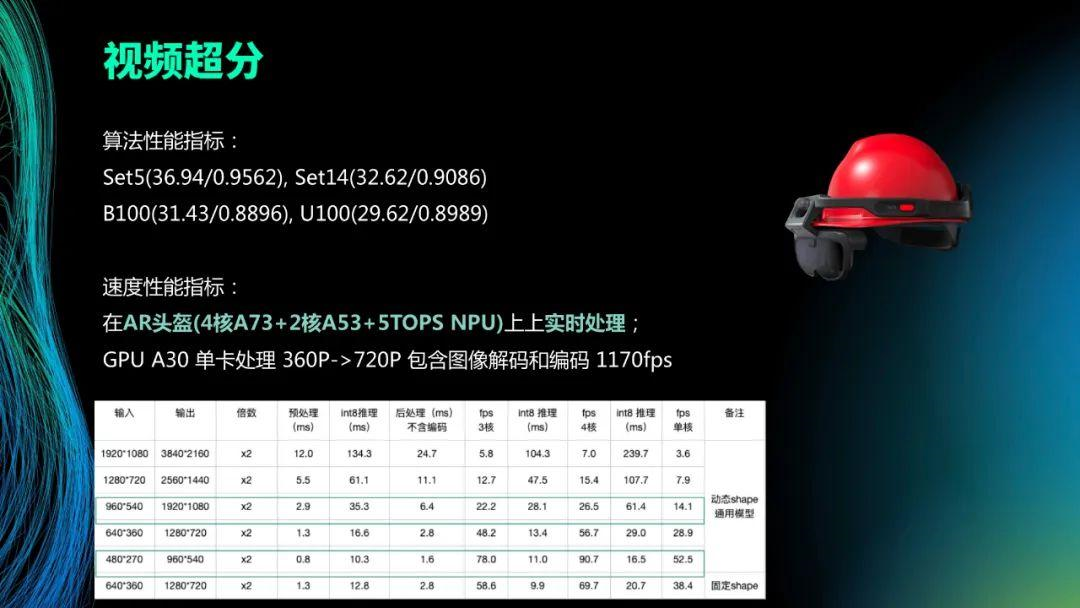
图中是工程加上模型块达到的效果,头盔上面是实时的四核的A73加上两核的A53还有5 TOPS NPU,上面的算法性能就是大家做超分基本数据集的PSNR提升。如果我们把整个模型的input输入比固定下来的时候,NPU的优化程度会更高,它就能从28提升到38。 当然,我们也在服务端的A30单卡上做了测试,把编解码都算进去大概1170fps,
这个是我们自己做的一个测试集视频,左边会是超分后的,右边是没超分的,一次下雨天测试录的。
开放式的喇叭在弱网下本身听起来就会比较吃紧不清楚,如果再发生丢帧的话效果就会更差,所以我们针对这一点专门做了音频的补偿。当然,音频的补偿其实本身的历史也是从LPC技术切换到深度学习的方式做。Web RTC其实也改成用深度学习的方式,大家很多都在用GAN的方式去进行丢包生成。我们本身的操作就是模拟丢包率在10%到30%之间,整个丢包时长最长的大概是120毫米之内,然后验证PESQ的效果。这个基于的是在DNS挑战赛的模型上做优化。

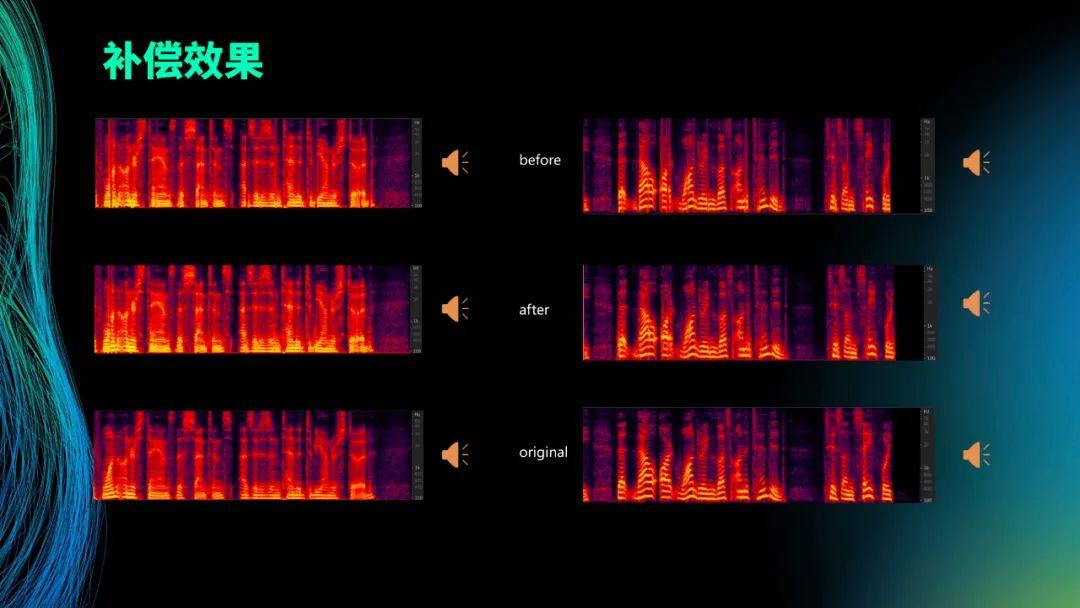
这里给大家放一下效果。最上面的是丢包处理之前的。第二个是处理后的声音频谱图。第三个是最原始的声音小的。从图上可以看出来,凡是竖线的就是丢数据造成的,凡是一整条竖线从上面画下来,修复之后就会少很多。图像识别跟原始图像很接近,就说明你恢复的越接近。
刚才有提到AR、VR里Audio Focus是一个全局感受野。我们怎么样能够把真实声音的方位感给还原出来?这是我们其中做的一件事,就是空间声场。这里跟B端刚刚讲的3个不一样的点在于B端上的那些都是属于真实有用的。而C端更偏向于使沉浸感更好。你要说没有它可不可以?可以。但拥有空间声场的好处就在于,在真实RTC通信的时候,能使得语音到了之后能分清这个人在我的左边还是右边,以及在大概什么位置,把真实空间位置感还原出来,包括转头转向谁说话。转向谁说话这个方向的声音会大是一样的。像在线教育、在线会议,尤其是在线的社交里面应用会比较多一些。
声音的发展情况,最开始的空间表达上是单声道、双声道,后来的5.1、7.1属于平面上有五个喇叭加一个低音炮,再到5.1.x、7.1.x,就是空间布局上也会加喇叭,但这些还是个体不连续的。再发展到编码的维度上来讲就是我们从最开始单声道到面向对象的编码。比如大家经常到电影院看 3D电影,把整个炮弹或者是其它的战争打起来的时候东西飞过来的声音,整个朝你逼近过来,你会感觉很真实,因为它是把这个对象,不管是炮弹还是其它武器的发出的声音按照空间喇叭的位置跟你以最接近的路线给你播出来,所以你才会有真实感。再到后面就是面向场景的,像HOA的技术就意味着我尽可能地把任何东西都还原,不只是人为处理过的局部。从XR的角度来讲,其实我们要做的就是把割裂的感觉,1是1,2是2变成沉浸式的,所以从C端来讲它的效果就是在往这个方向走。

我们自己定义空间声场是从产生再到传播,整个传播过程中因为在AR、VR里都会出现,声音出来之后,大家很多利用头传或者是其它方式模拟球体范围内声音的产生,然后再到球体范围之外的声音该以平面波,还是以一维的波动方程,还是该以三维的波动方程去模拟、仿真的时候,每个人需要根据自己的算力去平衡去简化的,同时需要考虑传播过程中涉及到的一些障碍物。我戴着AR眼镜确实走到了另一个地方被一堵墙隔了声音,要不要遮挡,怎么去遮挡?包括经过那些东西的反射吸收了多少,还剩多少。这些都是去考虑的问题,再到编解码的模块定义外面的一些全景声能不能导到你这里进行播放。这是对于模块的一些定义。
整个空间声场的难题在于声场的仿真。波动方程很多都没有解析解,只有数值解,因为实时计算出来的东西没有固定的表达公式能够所有位置都做到,它只能不停地迭代。包括开放式喇叭带来的效果,因为现在大家仿真生产的时候都是按头传去做的,先不说投传的精细度做到什么程度,它仿真出来的结果是建立在到你耳道里面的声音,实际上AR的喇叭是在外面且还有30厘米,会导致声音发塞很厉害,听出来的效果会下降很多。
另外还有一个就是RTC中的传输。在线社交就像麦克,输出一些在线社交视频大家纯是在元宇宙里面跟你聊,但是你转过来,转过去的语音都是可以通过RTC的方式过来。这种尽可能地模拟真实场景说话的方式跟RTC的传输也有关系。

因为空间声场是喇叭。假设这里面有5.1个喇叭,其实都很难听出一个比较明显的效果。这是虚拟的一个音响,你靠的近声音会很大,你一旦背对着它声音会越来越小,隔着门可以听到房间里的一个虚拟声音在发声,但是进来把门推开的时候声音会变得很大。这就是传播中的一个遮挡问题。大家只要带着同一个眼镜,同一个东西你走到这都可以听到它。
04 AR RTC的一些挑战
最后跟大家说一下AR下RTC的一些挑战。

第一个就是极低功耗,这些功耗是算法本身性能跟资源消耗之间的一些balance。因为我们自己的设备都是AR终端,如何减少功耗、减少发热、增加设备使用时常,始终是我们在终端上做的一些探索。另外,音视频到达设备之后,我还能够用哪些手段把音频的音质增强,视频的画质增强呢?
第二块涉及到弱网。大部分低端应用的场景就是恶劣的环境,所以很多算法就是针对弱网优化的,包括我们正在做的也会涉及到音频的超分,也是解决同样的问题。
第三块就是360度的超清高刷画面。其实在VR里面它的刷新率目前最高可以到240Hz,分辨率是有在4K并且还是全方位的。在我们AR里面,比如FOV大几十度,随时切进这么大的画面就是对RTC的挑战。实时视频该怎么去编?因为以前视频是实时基于上一帧、下一帧能够进行预测编码,冗余度很强,但是如果现在这样随时切该怎么做?不过当下行业里也已经都在思考这个问题,推出新的3D编码方式。
还涉及到一个点是虚拟模型里面通信的东西怎么跟RTC一起发走。比如RTC有时候这里还跟富媒体有关系,就是RTC更新的时候除了音频、视频、文字流之外,我们还有图片、2D或者3D的模型,包括一些办公文件。当然这些东西不见得一定得进RTC的协议里面,但是起码我们实时处理的时候遇到了问题。
以上就是我给大家带来的AR×RTC的一个分享,包括遇到的一些点跟针对这些点我们做的一些技术应用与思考。谢谢大家!

@2017-2024 LiveVideoStack版权所有. 京ICP备20010033号-1  京公网安备 11010502042092号
京公网安备 11010502042092号







