编者按:在贷后催收行业中,每个公司每天的录音量可达上万小时,因此语音识别功能对其非常重要。今天 LiveVideoStack 大会邀请到了洞听智能的张玉腾老师,为我们介绍在坐席辅助系统中,语音与文本的碰撞。
大家好!我是青岛洞听智能的算法工程师张玉腾,我们公司在去年四月份成立。在 2016 年,我们已经是联信集团的一个智能化部门,一直在做语音与文本相关的算法工作。
01 坐席辅助系统介绍
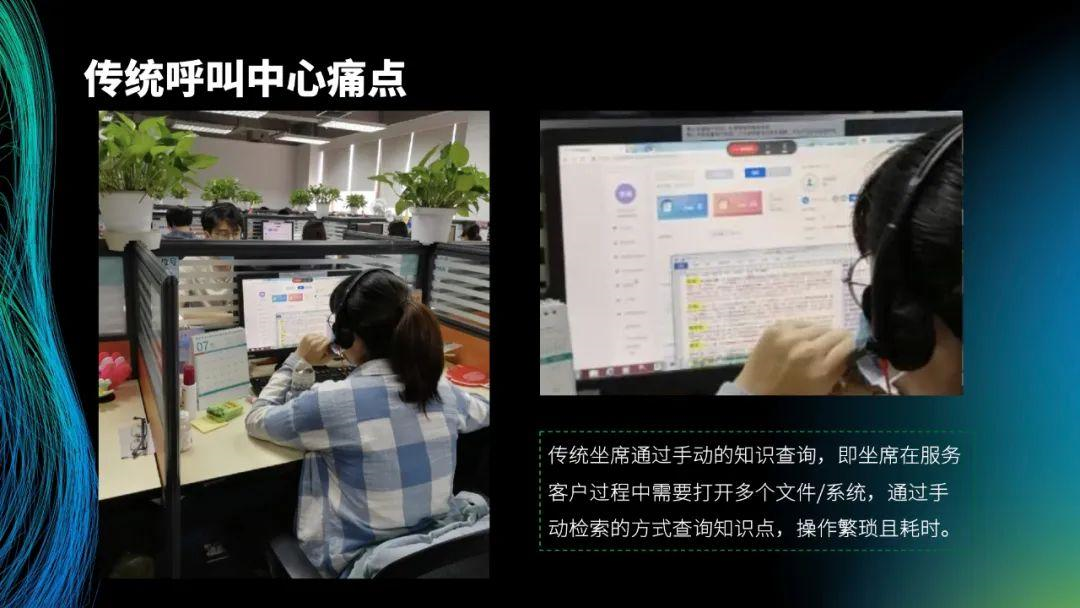
首先,介绍坐席辅助系统中传统呼叫中心的痛点。传统坐席通过电话与客户沟通,并且需要手动地查询知识,即坐席在服务客户过程中需要打开多个文件,通过手动检索的方式查询知识点,操作繁琐且耗时。

我们想解决的第一个痛点是:新手岗前培训难,技能提升慢,离职率高。首先,存在业务知识多、复杂的问题,我们的业务主要是贷后催收,其中涉及到很多法律知识。有些客户逾期还款,可能是因为客户遇到了一些重大事故,比如家人生病,公司出现问题等,而并非客户不愿还款。此时,我们一方面要帮助银行追回借款,另一方面也要帮助客户(欠款人)解决生活中遇到的问题,因此我们建立了大量的知识库来帮助解决各类法律问题。新人的培训周期大概有两个月(新人指工作期限不满六个月的员工),而培训周期长也是一个较大的问题。此外,还有日常学习不及时的问题,这是因为银行的催收政策会根据央行的指示实时地变化,并且每个银行的催收策略不同,比如减免政策、逾期归还的最短时效等。催收政策可能在一个月内或半年内发生改变,如果不能及时地更新知识库,法务在催收的过程中会由于信息不对等而被客户投诉。最后,解决监控指导的问题是为了帮助管理层实时监督法务,使其在与客户沟通的过程中避免发生争吵,降低投诉率。

我们想解决的第二个痛点是:运营监控不及时,风险防范严重滞后。首先,大部分一线坐席的年龄在 28 岁以下,新人占比较高,每家分公司的新人占比大概在 40% 至 60% 之间,并且每个月会出现大量的人员变动。然后,工作内容比较单调,正常情况下每个坐席每天的通话时间在 5 至 6 个小时。此外,任务比较繁重,每个坐席每个月在手的案件量高达 500,即每个月需要与 500 个欠款人沟通。再者,坐席的情绪波动较大,欠款人在被催收的过程中可能会抱怨和谩骂,坐席的情绪易受影响。最后,还有督导滞后的问题,质检和培训滞后,已发生的风险无法及时处理,负面影响很可能已经产生。

以下是我们提出的解决方案,主要面向坐席和管理者。首先,会将坐席和欠款人的对话实时翻译成文本。然后,根据翻译的文本分析客户意图,向坐席自动推送知识和话术。另外,黄色方框表示预警提醒,实时监控坐席与欠款人的对话,发现风险后实时给坐席预警,并通知监管人员,防止发生投诉。坐席地图方便管理者查看分公司或小组的坐席的工作情况,比如打了多少通电话,通话中没有解释清楚多少业务点。
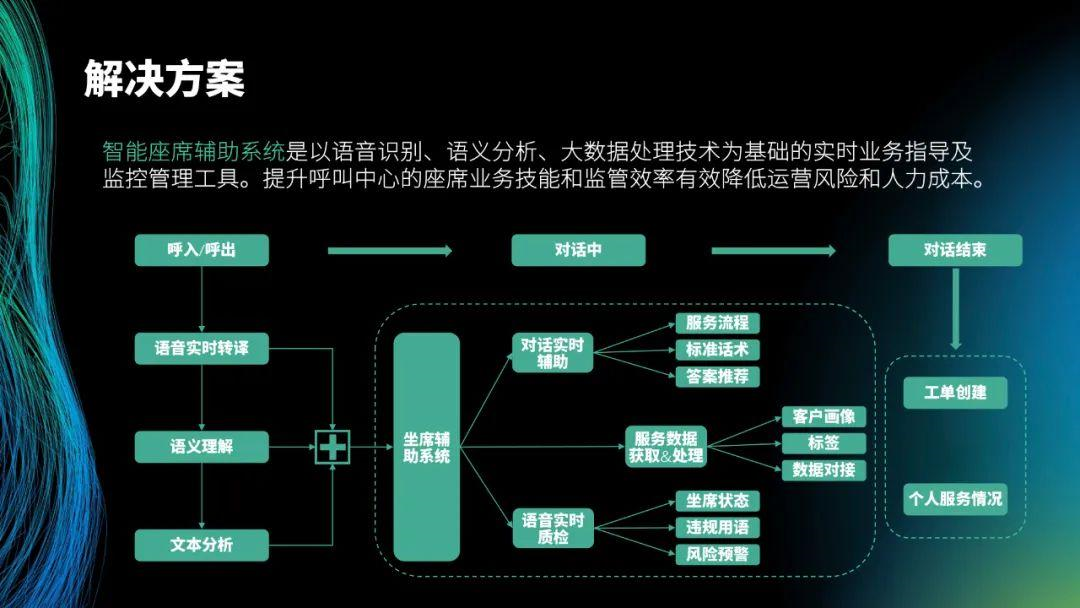
解决方案的核心就是这个流程图。呼叫中心呼出后,在呼叫系统接入插件提取音频流。然后,对提取的音频流进行语音识别、语义理解和文本分析。最后,将其传送到坐席辅助系统的对话实时辅助和语音实时质检,并将提取出来的数据(客户画像、标签)推送到业务系统中。

适用的场景如图所示。
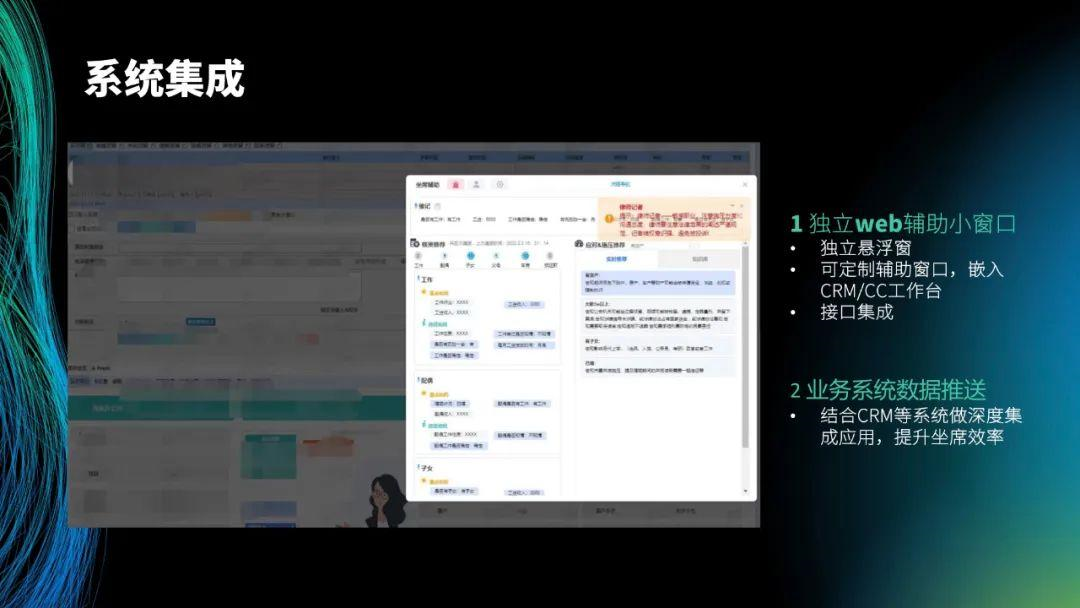
最后介绍系统集成。在各个系统中,只需要一套 js 代码并将其嵌入到 CRM 或业务系统中,就可以进行使用。
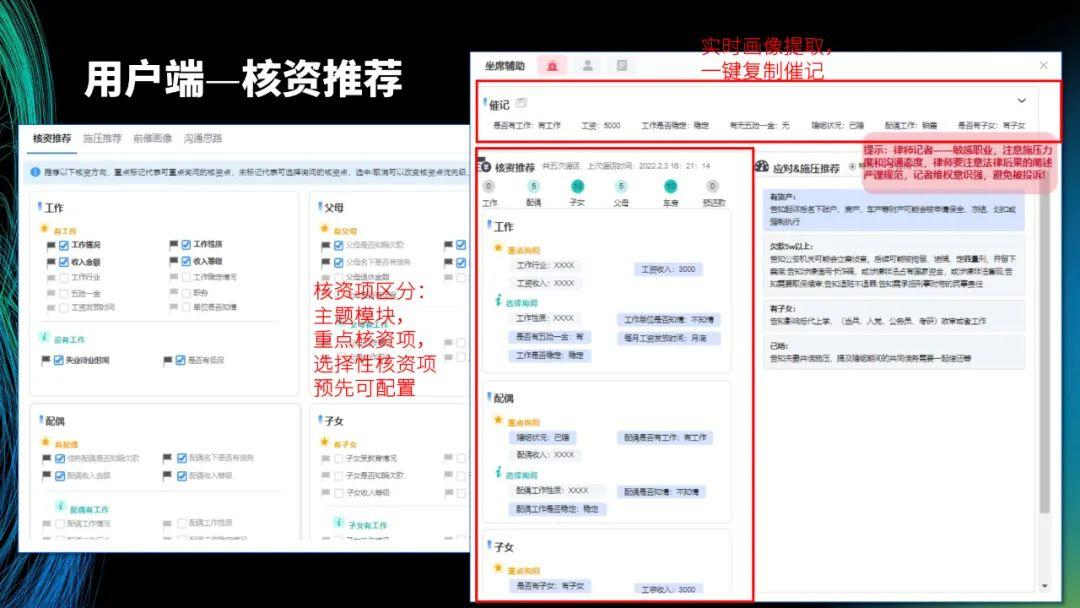
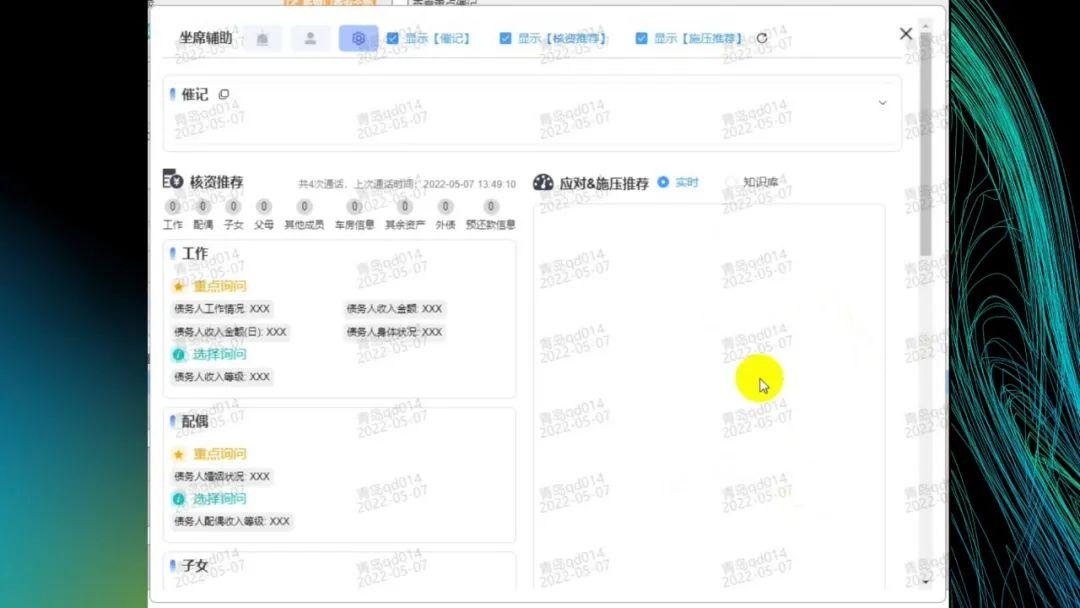
左图是预设,右图是核心部分,上面的催记是坐席在与欠款人沟通后,记录的欠款人的信息,比如是否有工作、工资、工作是否稳定、有无五险一金、婚姻状况等。这些信息以前需要坐席自己记录,现在可以直接生成,坐席可以一键复制。
核资推荐和应对施压是催收过程中的两大核心步骤。核资是为了了解欠款人的实际情况,应对施压是为了帮助坐席解决遇到的问题。

坐席可以快速检索知识库,这部分不详细介绍。

图的左边是实时翻译出的文字,上面是话术流程导航,每个业务有一套 SOP 流程,可以监督坐席在催收过程中是否有按照标准流程进行对话,其中绿色表示已完成该流程,灰色则表示没有完成该流程,因此可以实时监测坐席的催收是否合规。有些欠款人员是律师记者或保险人员,他们对相关法律比较熟悉,因此会提醒坐席在面对这类人群时要注意话术。
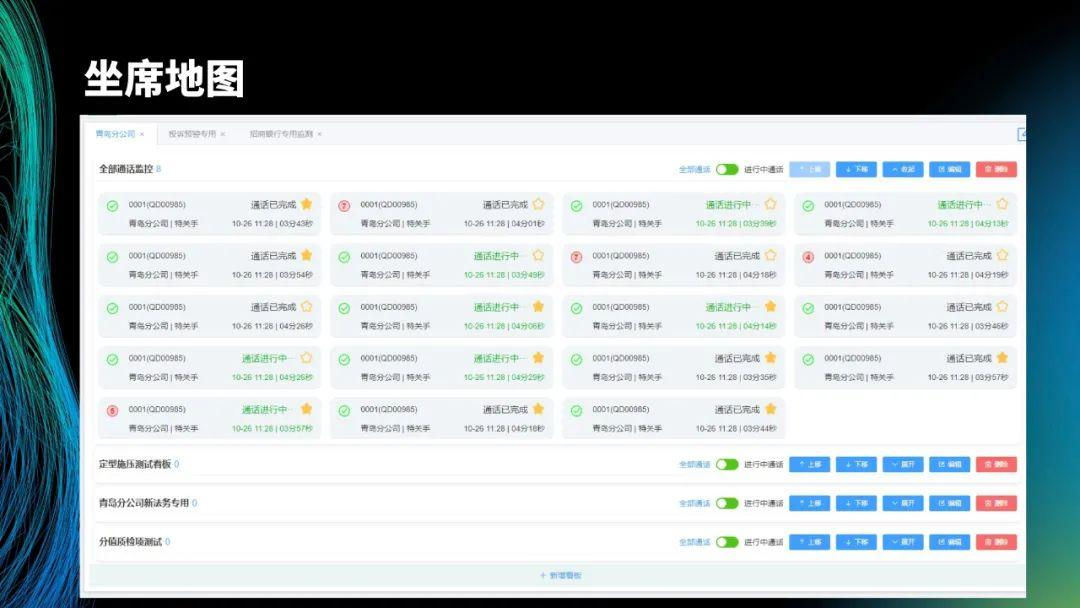
这里展示的是后台管理,可以看到每个坐席的通话状态。点击进入后,可以看到坐席当前的对话文本。
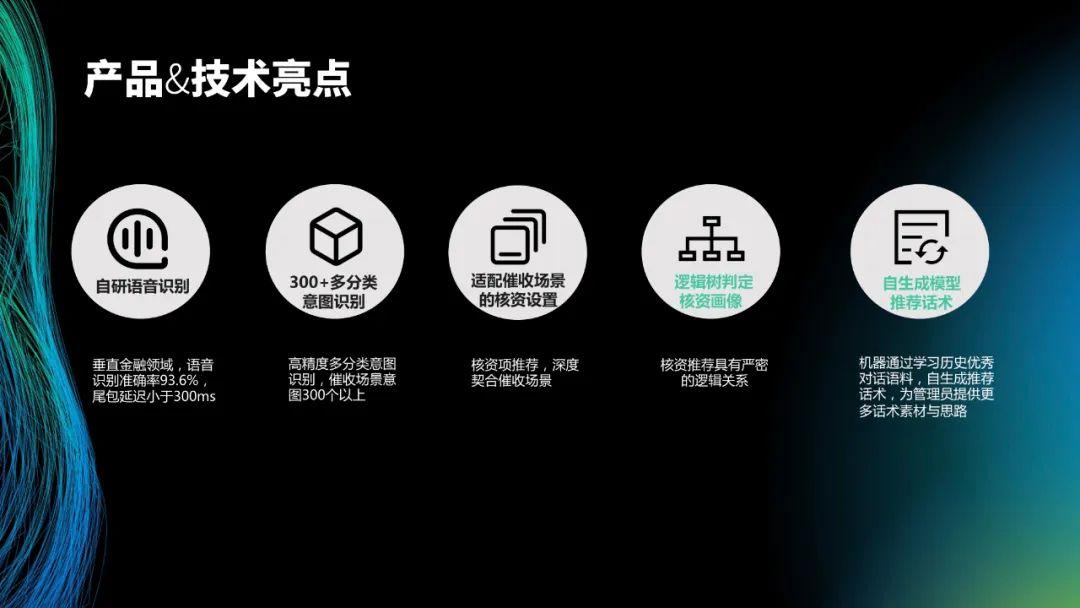
02 实时语音技术
接下来,介绍我们遇到的技术问题和解决经验。
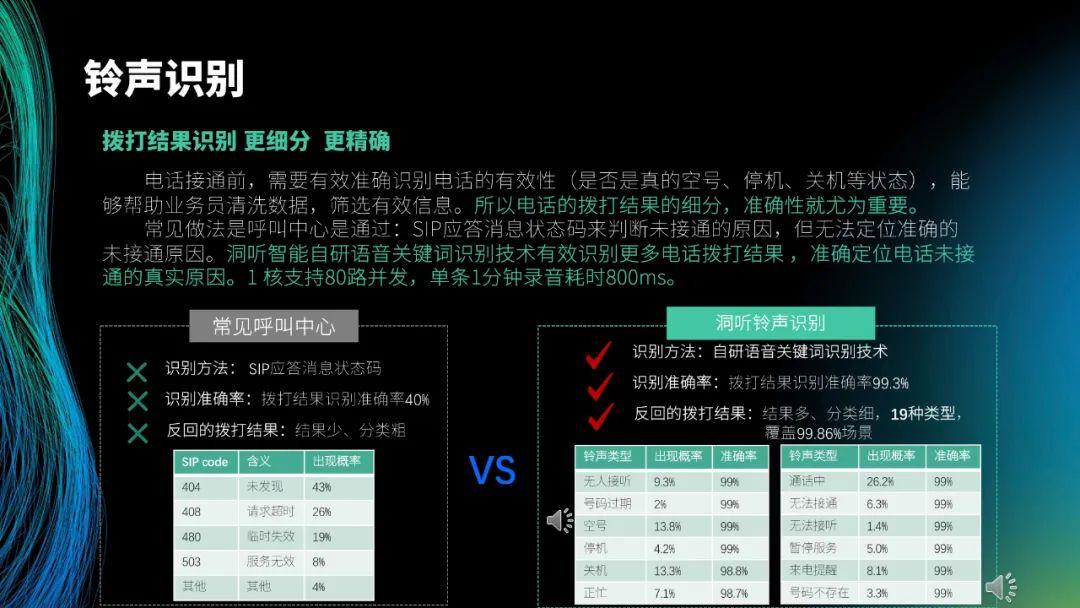
首先是铃声识别。整个对话会经过呼叫中心,电话接通前会有大段的铃声,由于业务的特殊性,电话接通率可能不足 10%,因此会存在很多未接通的电话。电话未接通时,传统的呼叫中心返回的 SIP 码包括 404、408 和 480 等,根据状态码判断电话未接通的原因,比如停机、空号和暂停服务等,但无法定位准确的未接通原因,而要根据实际的铃声决定后续拨打的策略。在第一版中,我们通过语音识别来完成铃声识别,最大的问题是会给语音服务带来很大的压力。为了提高效果,后续我们采用了语音关键词识别技术,将停机、空号、关机等未接通电话的相关铃声的音频片段作为指令词来训练模型。现在得到的模型,1 核支持 80 路并发,10 核就可以覆盖一天 40 多万的电话拨打,识别单条 1 分钟录音耗时 800ms,且识别准确率在 99% 以上。这里展示了一个录音,如果识别到类似的音频就判断为空号。
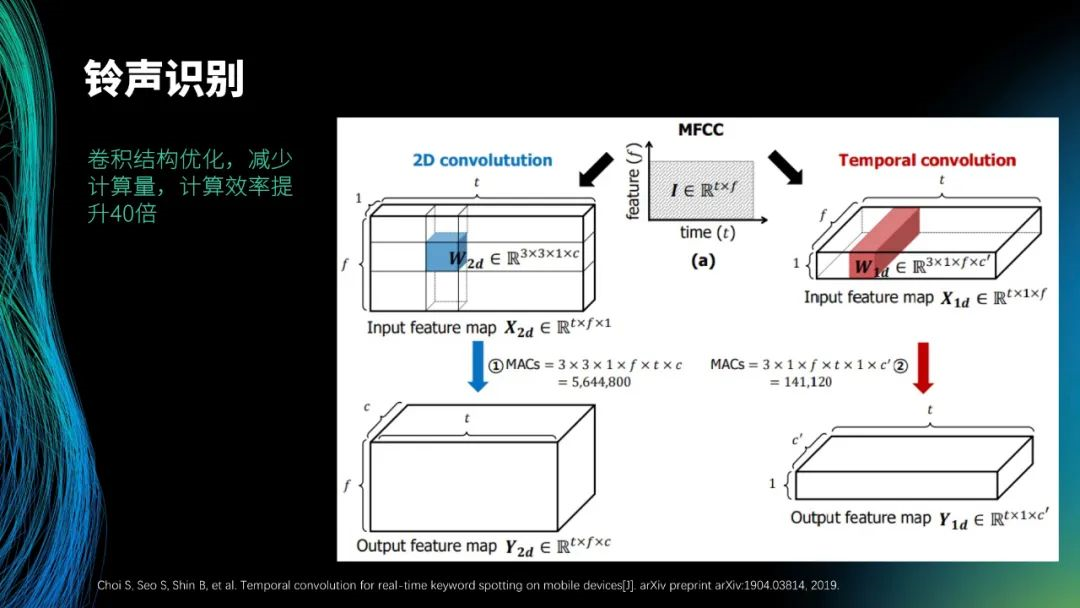
铃声识别的算法借鉴了关键词识别的算法结构,为了提高计算量,参考了图中展示的论文,将二阶卷积变成了时间卷积。二阶卷积中,需要从左到右进行相关操作,而在时间卷积中,只需完成一次从左到右的相关操作,故计算量减少了 40 倍。目前,整个模型的大小大约为 5 兆,系统的性能较高。
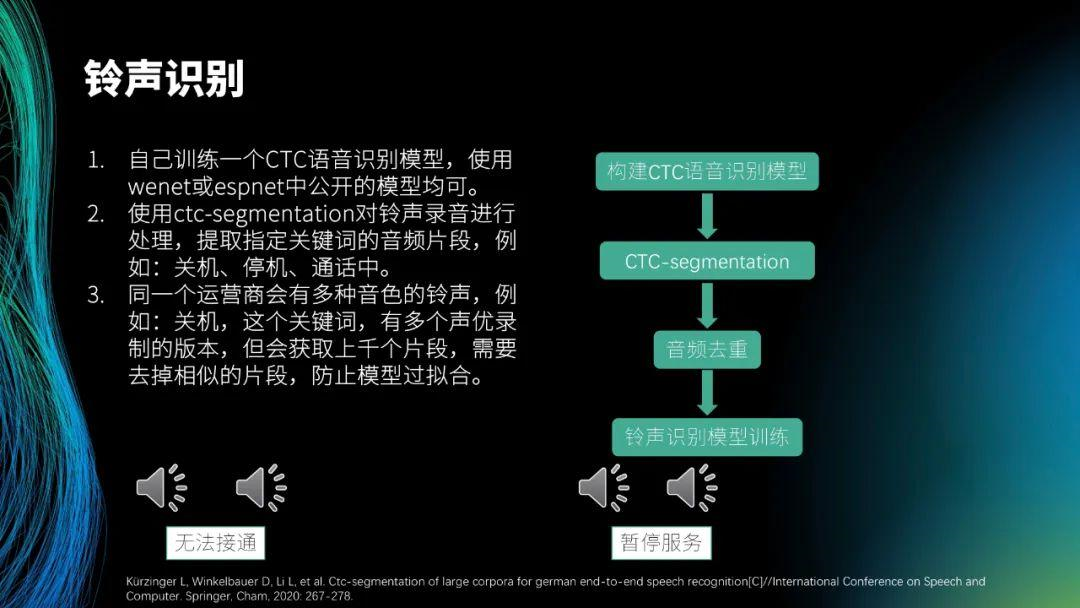
铃声识别的模型训练比较简单,只需将铃声片段提取出来即可,故难点在于铃声片段的提取。我们自己构建了 CTC 语音识别模型,大家若想使用相关模型,可以使用 wenet 或 espnet 中公开的模型。找到模型后,再采用 ctc-segmentation 方法提取铃声片段,得到关机、停机、通话中的音频片段。得到音频片段后,就可以构建铃声的数据集,提取出常见铃声的关键词后,还要提取其周边的关键词。然后,就可以进行模型的训练。
如图,提取了关键词为无法接通的音频片段作为数据集进行模型训练,所有的代码可以在图中展示的论文中得到。

我们从 2019 年开始做语音识别,这是因为集团有相关的需求,每天的录音量可达上万小时。我们最初买过阿里、腾讯等的语音识别产品,但其产品的识别率达不到我们的要求,于是我们开始自己做语音识别。最初,我们使用 KALDI。然后,我们选择使用 ESPnet,但 ESPnet 只能处理离线的任务,且必须 GPU 在上运行。wenet 在 2021 年 1 月份开源,我们就开始使用 wenet 模型。
我的心得体会如下。
首先,离线模式下使用 GPU 更好,因为从我们的实践经验来看,实现 BatchBeamsearch,性能会成倍提升(不过目前 batch 的搜索没有成熟的开源的方案,需要自己写),并且在单张 2080ti 上可实现 100 路并发,按单并发的成本计算,提升了 40 多倍,即大幅度地降低了成本。
其次,LM(语言模型)会带来负优化,大家使用在线语音识别时,可能会看到一些热词出现,这时通常会采用语言模型来优化场景里的关键词。我们分析了语言模型带来负优化的现象,发现造成这种现象的原因是我们的通话内容偏向通用领域(通话过程涉及生活中的各方面),所以语言模型会带来负优化。
另外,libtorch 1.10 存在性能问题,在 facebook 上发布 libtorch 1.10 后,很多人反映使用时遇到了一些性能问题。官方表示 libtorch 1.10 会带来一定的性能提升,在第一次模型启动的推理过程中,会根据请求的数据大小进行算子的优化。但实际试验后,发现第一次算子优化的耗时非常长,会使性能降低 3 至 4 倍,并且优化结束后,速度仍很慢。后来我们发现,libtorch 1.9 版本的性能最佳。
此外,libtorch 全版本存在内存泄露的问题,长时间推理后内存会爆掉。针对这个问题,我们向 wenet 推送了一个内存优化的方案,即用 jemalloc 替换自带的 malloc。
再者,pytorch 和 tensorflow 偏向训练框架,在进行日常推理时,性能并不高,于是我们采用 onnx 进行了转换。采用 onnx 一方面是为了模型的统一,另一方面是因为 onnx 有 onnxruntime,而 onnxruntime 是专门为推理设计的,因此能带来 20% 的性能提升。但在一些高核心的 CPU 上,进行多并发时,会带来 5% 左右的性能下降。这是因为普通的英特尔的 CPU 一般有 16 个物理核(32 个虚拟核),我们可以做到 32 路并发,而之后我们在 AMD 机器(每个机器有 64 核)上进行 64 路并发时,发现性能下降。我们后来在网上发现其他人也提出了类似的问题,因此在高核心的机器上,我们仍采用 pytorch。
最后,在 AMD CPU 上有 AVX2 指令集的可以通过 fakeintel 启用 mkl 对 AVX2 的优化。之前提到,英特尔会做开源的软件,但针对自己的 CPU 会有很多隐藏的优化。mkl 是一个闭源的商业软件,对矩阵优化有 20% 的提升,但经 mkl 优化后的矩阵向量库在 AMD CPU 上会带来负优化的问题,对此可以通过预载入掩盖 mkl 对 CPU 的判断。
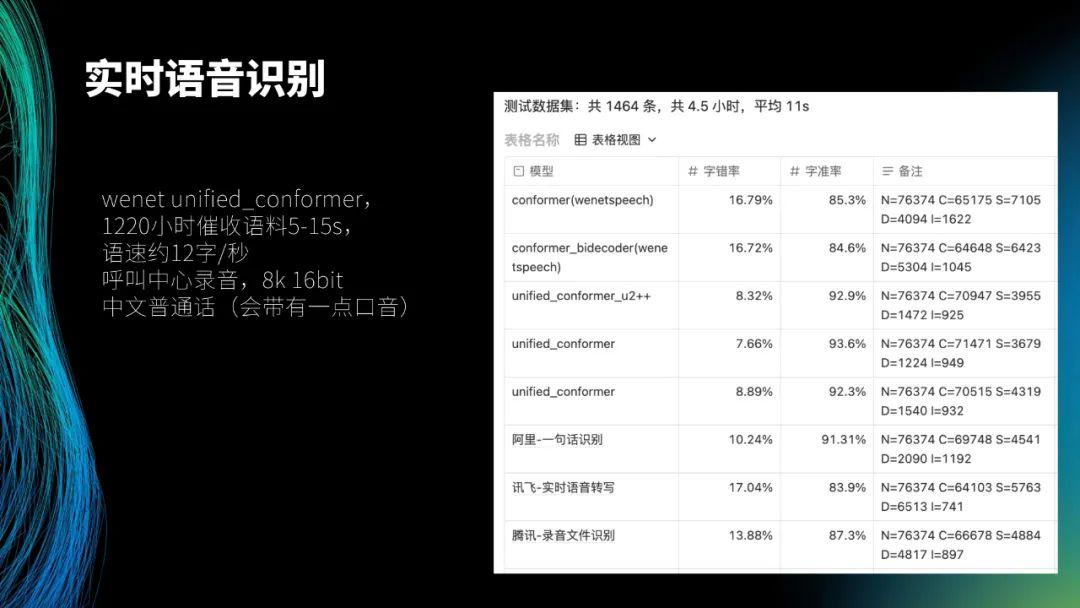
这是我们内部的一个测试集,左侧是使用的模型结构,叫做 unified_conformer(wenet 上的一个开源模型)。我们内部已经积累了 1220 小时催收语料,平均时长为 5-15s,语速约 12 字 / 秒。可以看出语速非常快,这是因为通过快速对话可以减少欠债人的思考时间,给其带来压迫感,这也是由催收场景决定的。所有的录音来自于呼叫中心,音频格式都为 8k 16bit。语言是中文普通话(会带有一点口音)。
测试数据集共 1464 条,共 4.5 小时,平均时间为 11s。前两个 wenetspeech 的数据集是去年 wenet 社区开源的一万小时数据,是一个开源的最大的中文数据集,也在很多场景中取得了一些结果。这两个 wenetspeech 开源的模型的字错率都为 16%,字准率分别约为 85% 和 84%,故在我们的业务场景下无法使用这两个模型。后三行数据分别是在阿里的一句话识别 API、讯飞的实时语音转写 API 和腾讯的录音文件识别 API 上得到的结果,效果最好的是阿里,其字错率为 10.24%,字准率为 91.31%。中间三行是我们自己测试的模型结果,可以看到,效果最好的是 unified_conformer,其字错率为 7.66%,字准率为 93.6%。

这是使用 jemalloc 替换自身的 malloc 后,libtorch 的内存泄露现象。左侧是替换以后的结果,右侧是没有替换的结果。实验场景是在 40 路并发下,模拟 5 次请求,每次请求停留 10s 至 30s 左右。从右侧的图可以看出,在 5 次并发后,内存被占用了 12G,即占用的内存开始保持增长趋势,增长到 12G 时趋于稳定。从左侧的结果可以看出,使用 gcmalloc 替换后,占用的内存不会超过 2G,基本保持在一个 G 左右,非常平稳。这个结果我们已经在社区提交,大家也对其进行了验证。

这是我们运行 mkl 库的加速的结果。上面一张图中,200 代表当前实时语音请求的并发数,黄色的线表示延迟超过 300ms 的包,当黄色区域与绿色区域基本一致时,可以发现其中有一半的请求数的包的延迟大于 300ms,即延迟较高。那么,如何使 mkl 库去识别 CPU 是否为 intel 的呢?可以直接写这样的代码,运行 mkl 时就会执行这个命令,并返回 1(表示 CPU 是 intel 的),然后执行 AVX2 指令集的优化。
下面一张图是优化后的结果。300 代表当前实时语音请求的并发数,可以看到没有一个超时。当并发数为 600 时,可以看到在后半段出现了超时的情况,但数量很少。在相同的计算资源条件下,在并发数为 500 的情况下,可以保证没有包的延迟超过 300ms。

03 自然语言处理技术
接下来,介绍自然语言处理技术。

之前的字准率大概为 93%,即 100 个字中会有 7 个字出错,因此想用文本纠错的方法改正这些出错的字。我们基本每月优化一次语音识别功能,因为要积累一个月的数据来进行优化。但是,可以每两三天就进行一次文本的优化,即每两三天更新一次纠错模型,就可以满足大量新词出现的场景。文本纠错的模型比较通用,其判断哪些字是错误的,然后判断哪些字是正确的。我们的数据集中有很多是由于发音错误导致的错字,因此决定 40% 用相同发音的字符替换,30% 用相似发音的字符替换,即 70% 的字符是用同音或相似音的字符去替换,从而得到错误数据。另外,5% 用相似笔画的字符替换,这里也可以不进行此类替换,添加这项替换的作用是提高模型的泛化性。最后,10% 随机替换,15% 保持不变。构建得到数据集后,就可以采用模型进行实验。举个例子,最近刚解除封控,在我们这个领域,很容易将 “风控” 语音识别为 “封控”,通过纠错可以将其改正。
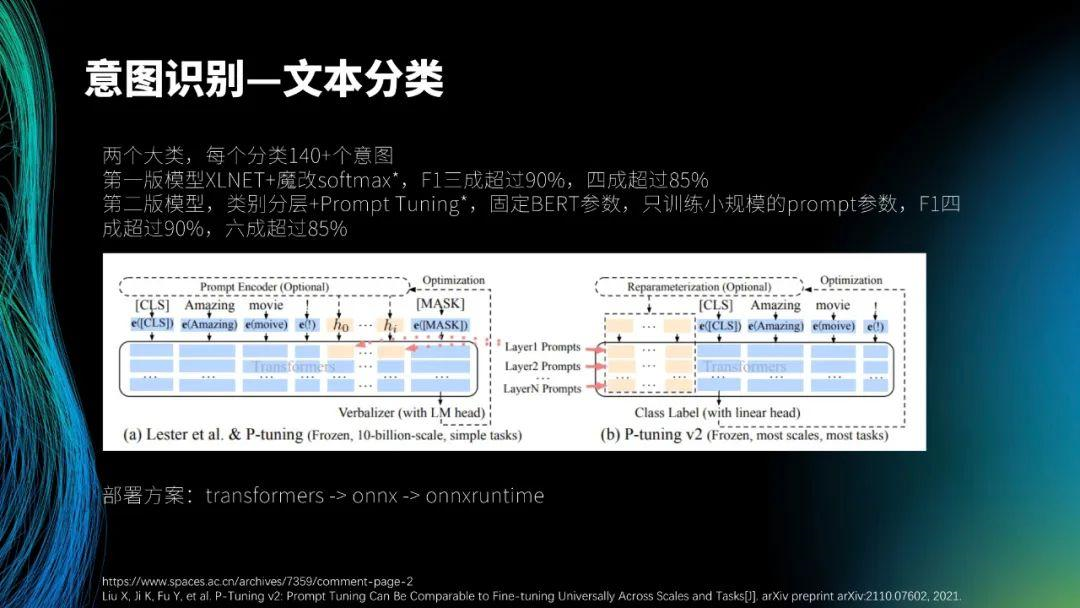
然后介绍意图识别。意图识别是坐席辅助系统中耗时最久的工作。最初,我们从全国调用了 30 多个专家到总部来做坐席辅助系统。可以看到,目前分为两个大类,每个大类有 140 多个意图,总共为 280 多个意图。其实,和 30 多个专家讨论一个月后,我们最初决定设定 1000 个意图,但发现其长尾效应特别大,近 600 个意图的样本数量为几个或几十个,不超过一百个。因此在与专家讨论后,根据实际系统和产品的性质,最终决定设定 140 个意图。对于一些意图分类模型来说,140 个意图是比较多的,尤其我们还是一个多意图模型(一句话可以包含几个意图)。
第一版模型是 XLNET + 魔改 softmax,大家可以看一下魔改 softmax 中的第一条引用文献。普通的 softmax 中,可以设置阈值判断哪几个意图是多分类的,但魔改 softmax 可以使模型自动判断有几个意图是多分类的, 并且阈值是动态的。在第一版模型中,F1 三成超过 90%,四成超过 85%。
我们想继续改造第二版模型,想做一个分层模型。首先,对 140 个意图进行归纳,然后定义 21 个大类,再在每个大类中分出几个小类。我们先做了大类模型,完成后发现准确率可达 95%,然后再继续做 21 个小的分类模型。这样的思路是好的,但在上线时却出现了问题。这是因为,21 个小模型加上 1 个大模型是 22 个模型,那么计算资源的消耗和机器成本就会非常高,需要很多 GPU,实际部署比较困难。为了解决这个问题,我们思考如何将 21 个小的分类模型变得更小。对此,我们采用了 p-tuning 技术,固定 BERT 参数,只训练小规模的 prompt 参数(只有几兆),然后将其与 BERT 融合,即训练时与 BERT 参数一起训练,但 BERT 参数不变,只训练小规模的 prompt 参数,就可训练得到 21 个小的参数。在实际推理过程中,BERT 参数(大概二百兆)加上 21 个小模型的参数(大概二百兆)组成约四百兆的模型,每个小模型得到了稳定的提升。训练完后,F1 四成超过 90%,六成超过 85%。部署方案是从 transformers 到 onnx,再到 onnxruntime。

目前,在和黄老师一起做一个探索的工作。因为在完成坐席辅助系统中我们发现知识的构建耗费了 40% 的时间,于是我们思考若要在一个新公司中部署这一套新的系统,如何快速总结梳理该公司原有的业务知识。因此,我们决定和黄老师合作完成一个自然语言生成模型。黄老师已经探索了自然语言生成领域很多年,并开源了一个大模型。
目前,我们想与黄老师合作完成的一个目标是,利用公司历史的所有对话数据(十万人人对话)进行模型训练,使其自己学习对话策略和话术。这样在一个新公司中部署这套新系统时,只用让其学习该公司的历史对话语料,就可让机器自生成推荐对话策略和话术。这个想法还在实践中,大家若有兴趣也可参与进来。
最后,演示一下我们这套系统。
我今天的分享到此结束,谢谢大家!

@2017-2024 LiveVideoStack版权所有. 京ICP备20010033号-1  京公网安备 11010502042092号
京公网安备 11010502042092号







